
一、Ragflow介绍
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
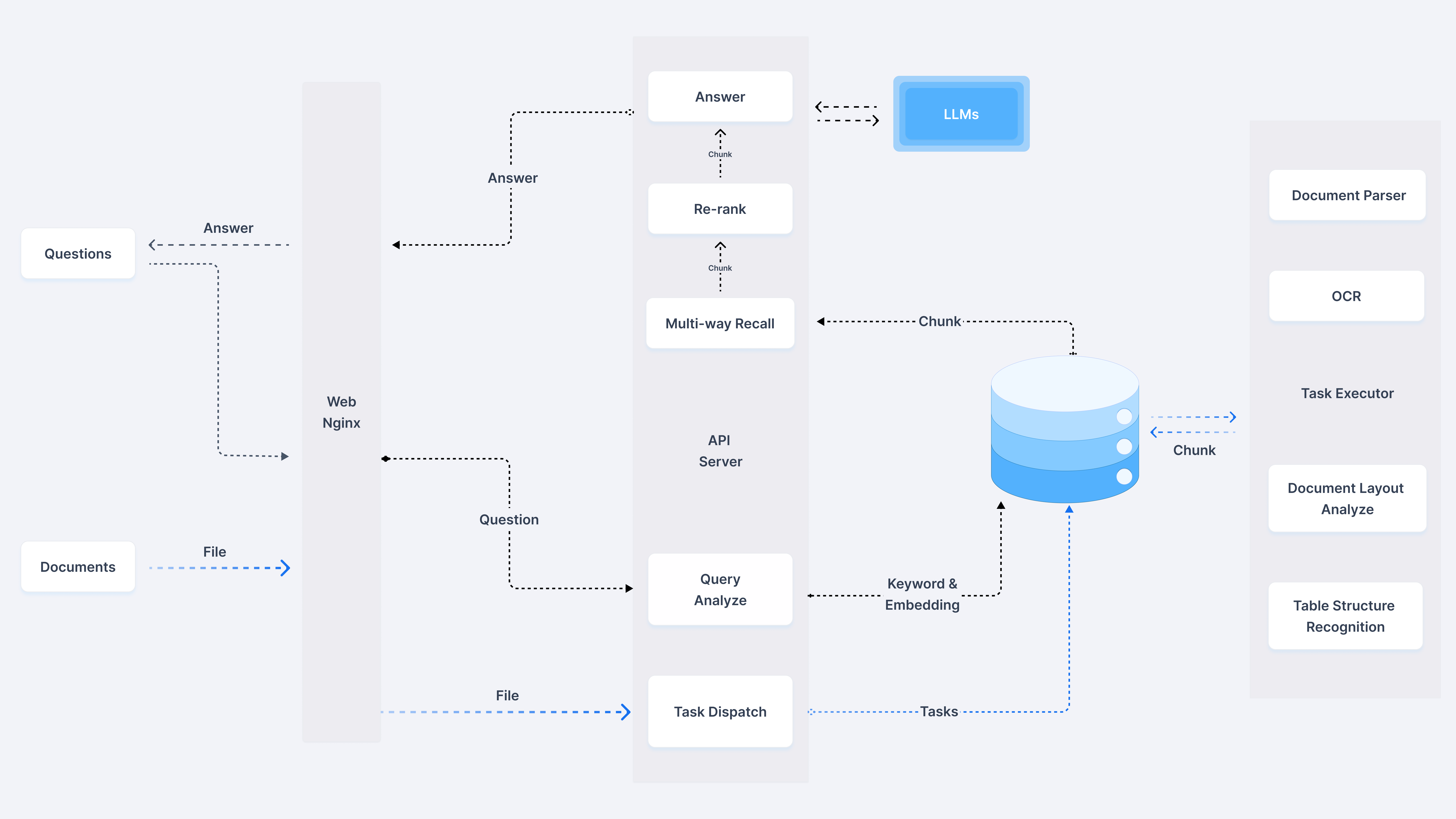
工作流程如下:
二、环境搭建
配置信息:
系统 MacOS 15
芯片 Apple M4 pro
内存 24G
cpu+gpu核数 14+20
python 3.11
Pycharm 2024.1.7
官方支持以编译好的docker镜像直接启动,但是由于我使用的是MacOS,官方还没有提供镜像支持,并且我需要断点调试查看一些信息,所以我这里以源代码启动。

首先到github克隆项目到本地(当前版本是v0.15.1)
git clone https://github.com/infiniflow/ragflow.git使用Pycharm打开项目,配置python解释器,并创建虚拟环境。

安装poetry
pip install poetry -i https://pypi.tuna.tsinghua.edu.cn/simple使用poetry安装项目依赖
poetry install依赖安装完成后,执行项目根目录下的download_deps.py,下载语料库等信息。
然后进入docker目录下,按需要修改.env文件的一些配置,可以配置es、mysql、redis、minio、infinity等信息,我这里直接采用默认配置。
其中mac用户需要将下面的配置置为1
# Optimizations for MacOS
# Uncomment the following line if your OS is MacOS:
MACOS=1修改完成后,使用docker compose启动依赖的服务
docker compose -f docker/docker-compose-base.yml up -d我这里启动后,报错mysql拒绝连接。
“Access denied for user 'root'@'172.18.0.1”从报错看是当前ip没有权限,可以在init.sql脚本中加入以下语句解决
GRANT ALL PRIVILEGES ON . TO 'root'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;如果无法访问HuggingFace,可以通过环境变量HF_ENDPOINT设置镜像源
export HF_ENDPOINT=https://hf-mirror.com修改hosts文件,添加域名解析
127.0.0.1 es01 infinity mysql minio redis确保你的终端已经进入虚拟环境
如果没有进入虚拟环境,使用命令激活虚拟环境。替换path/to/env路径为你创建的环境目录。
source path/to/env/bin/activate启动后端服务
export PYTHONPATH=$(pwd)
bash docker/launch_backend_service.sh安装前端依赖
cd web
npm install启动前端服务
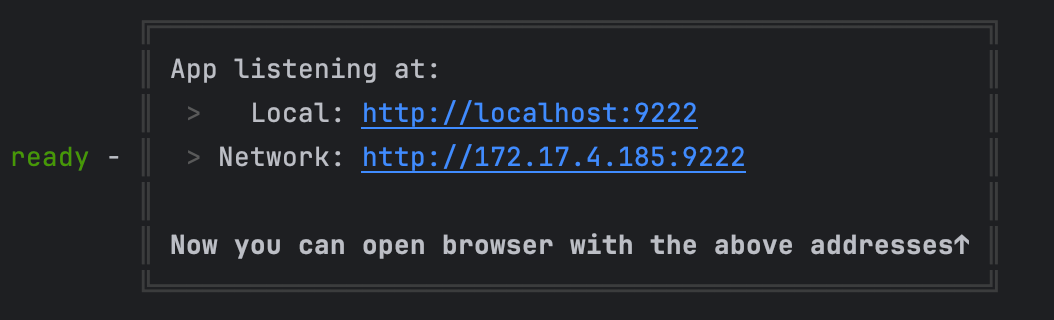
npm run dev 出现以下界面则启动成功
三、模型设置
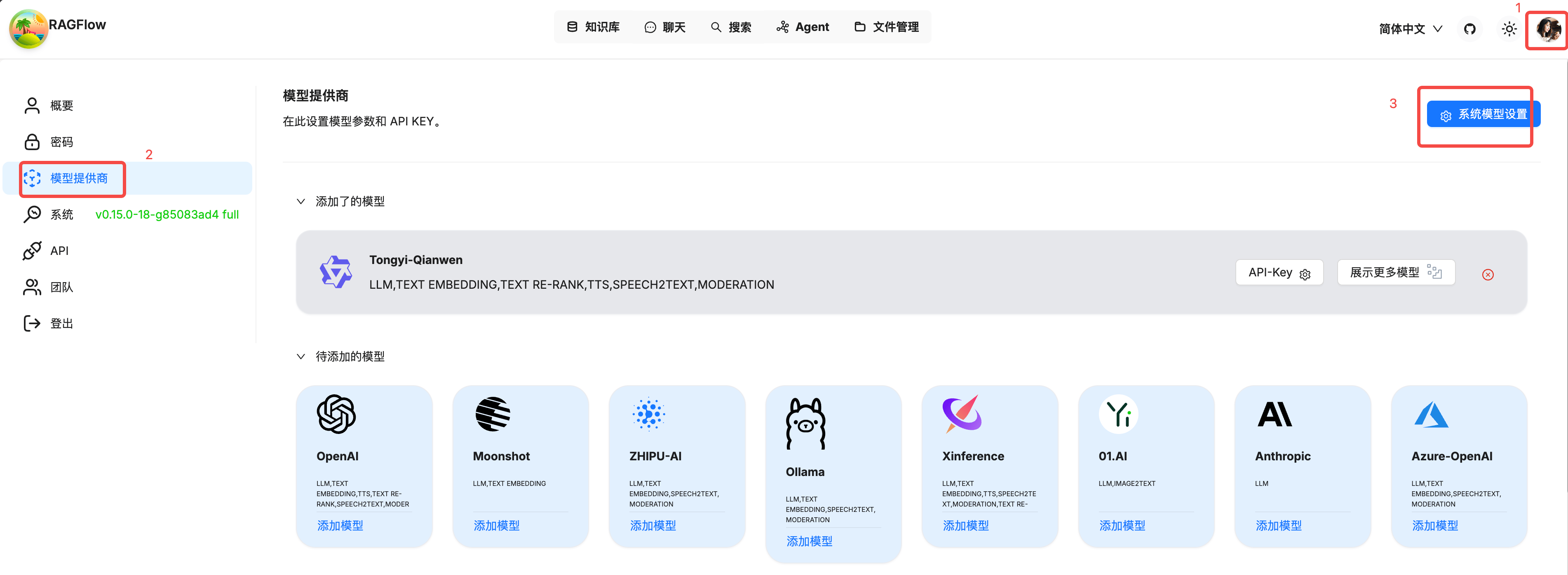
点击头像,打开模型提供商,点击系统模型设置。
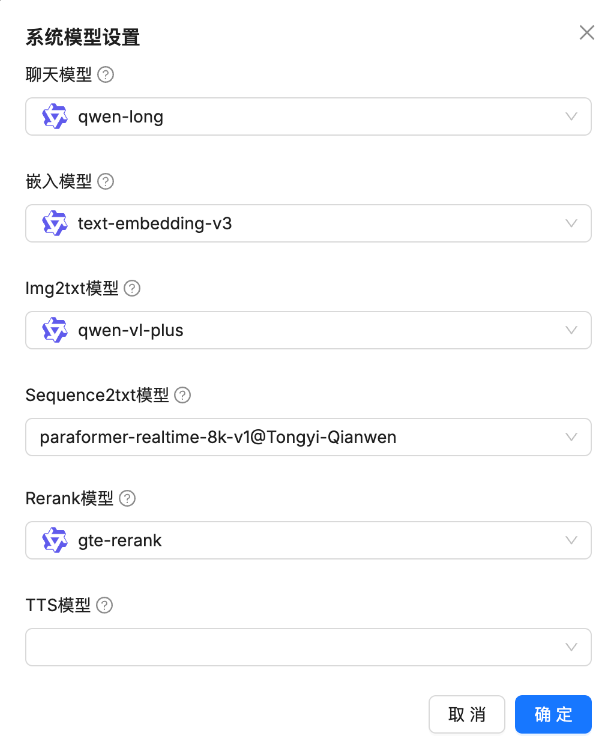
选择你想使用的模型,没有可以自己进行添加。
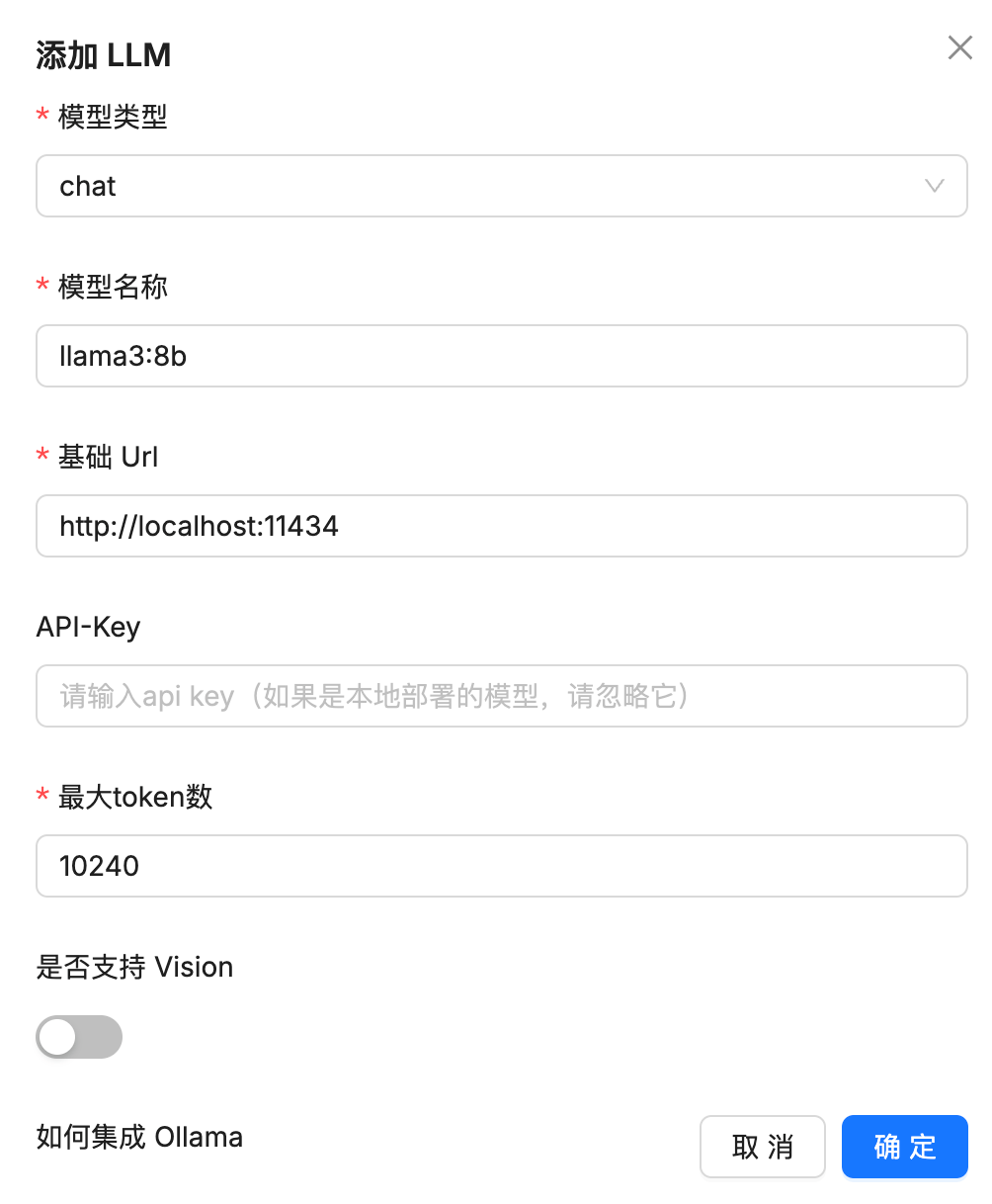
如果本地硬件支持的话,也可以使用本地大模型。本地大模型需要安装ollama
启动ollama后,在系统模型设置中进行配置
添加chat模型
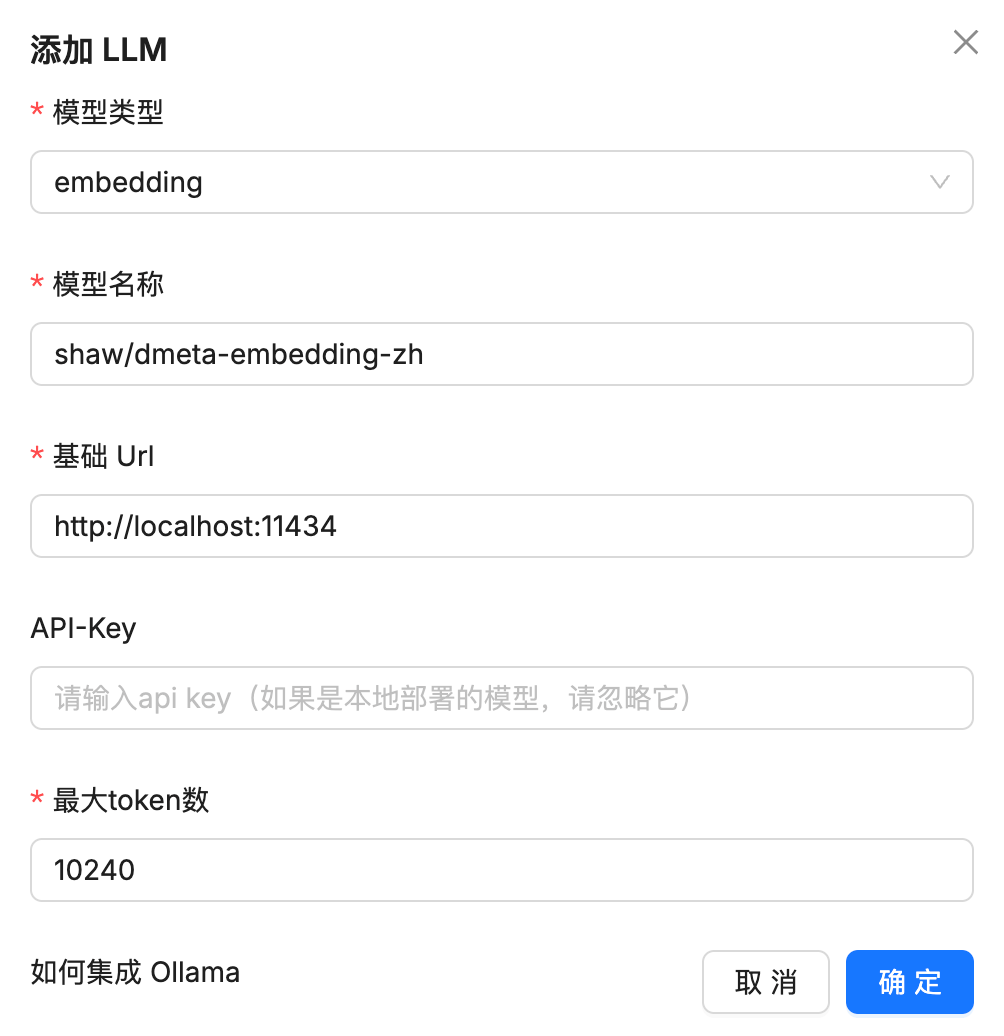
添加embedding模型
Tips:模型的选择
在挑选模型时,我们应该根据我们实际使用场景来选择模型,在效果与成本之间取得一个平衡。
我们的应用是否需要特定领域的优化或多语言支持。
考虑模型在相关基准测试(如MTEB)上的表现,选择性能最优的模型。
考虑信息的敏感性,以及模型的合规性和安全性。
开源社区的支持。
四、知识库搭建
访问太平洋健康险官网的公开披露信息,找到产品信息https://www.cpic.com.cn/jkx/gkxxpl/jbxx/gsgk/jydbxcpmljtk/zbcp/?subMenu=1&inSub=3
下载所有产品的pdf文件(这里推荐使用github的开源项目Scrapegraph-ai智能爬取)
准备好产品信息的文件后,访问ragflow页面,创建知识库。

配置知识库
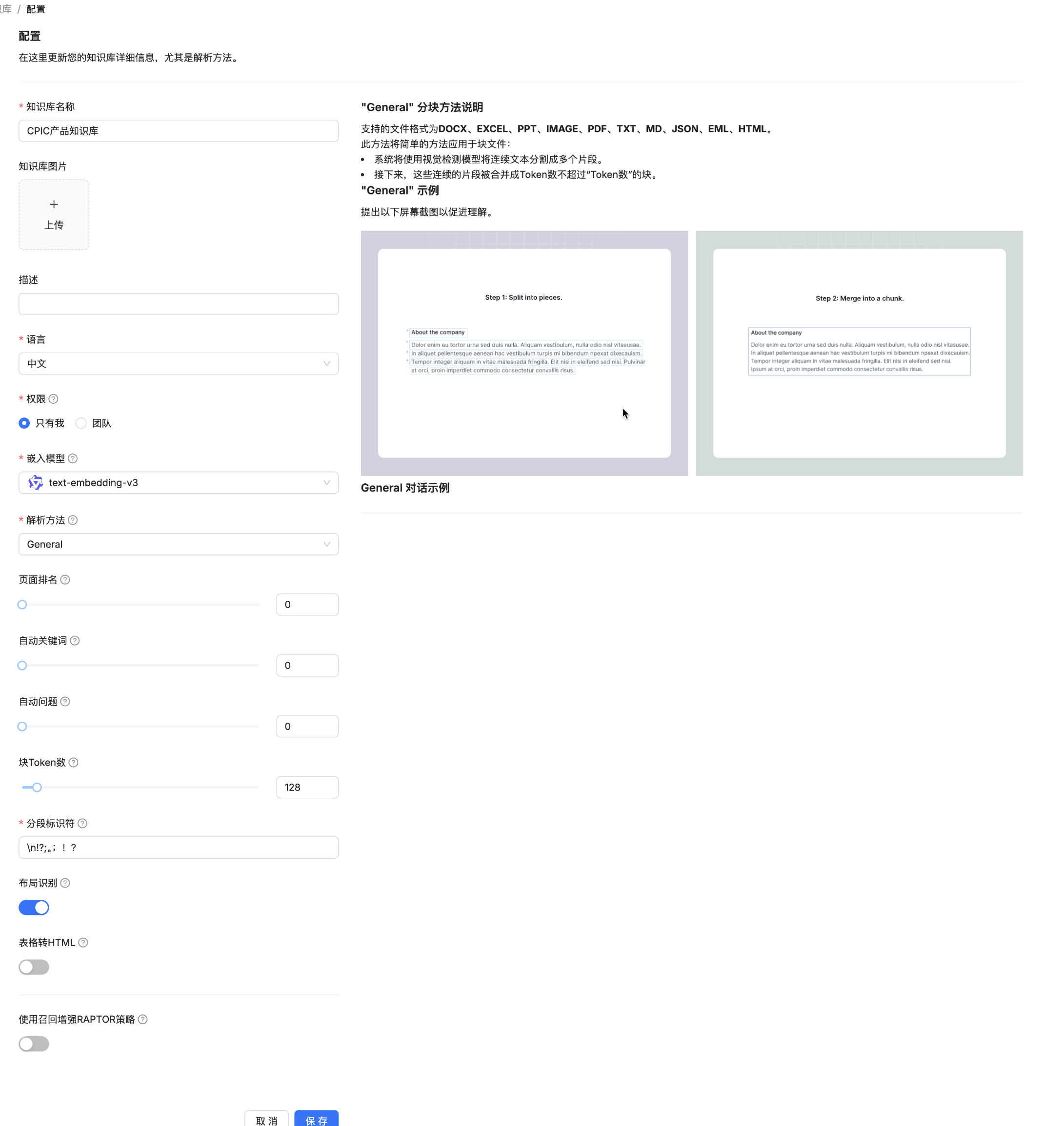
解释下其中的几个参数:
嵌入模型:用于嵌入块的嵌入模型。 一旦知识库有了块,它就无法更改。 如果你想改变它,你需要删除所有的块。这里可以选择内置模型(需要硬件支持),也可以使用大模型厂商提供的模型,我这里使用的就是阿里的text-embedding-v3模型。
解析方法:决定文档的分块方式。
General:默认方式。使用视觉检测模型将连续文本分割成多个片段,这些连续的片段被合并成Token数不超过“Token数”的块。
Q&A(问答):仅支持 excel 和 csv/txt 文件格式。
如果文件以 excel 格式,则应由两个列组成 没有标题:一个提出问题,另一个用于答案, 答案列之前的问题列。多sheet只要列正确结构,就可以接受。
如果文件以 csv/txt 格式为 用作分开问题和答案的定界符。
Resume(简历):将简历解析为结构化数据。
Manual(手册):仅支持PDF。手册具有分层部分结构,我们使用最低的部分标题作为对文档进行切片的枢轴。 因此,同一部分中的图和表不会被分割,并且块大小可能会很大。
Table(表格):仅支持EXCEL和CSV/TXT格式文件。对于 csv 或 txt 文件,列之间的分隔符为 TAB。第一行必须是列标题。列标题必须是有意义的术语,以便我们的大语言模型能够理解。 列举一些同义词时最好使用斜杠'/'来分隔,甚至更好 使用方括号枚举值,例如 'gender/sex(male,female)'。
Paper(论文):论文将按其部分进行切片,例如摘要、1.1、1.2等。
Book(书):由于一本书很长,并不是所有部分都有用,如果是 PDF, 请为每本书设置页面范围,以消除负面影响并节省分析计算时间。
Laws(法律文件):法律文件有非常严格的书写格式,使用文本特征来检测分割点。
Presentation(演示文稿):支持的文件格式为PDF、PPTX。每个页面都将被视为一个块。 并且每个页面的缩略图都会被存储。
One:对于一个文档,它将被视为一个完整的块,根本不会被分割。
Knowledge Graph(知识图谱):文件分块后,使用分块提取整个文档的知识图谱和思维导图。此方法将简单的方法应用于分块文件: 连续的文本将被切成大约 512 个 token 数的块。接下来,将分块传输到 LLM 以提取知识图谱和思维导图的节点和关系。
页面排名:这用于提高相关性得分。所有检索到的块的相关性得分将加上此数字。 当您想首先搜索给定的知识库时,请设置比其他知识库更高的 pagerank 得分。因为可以在聊天中同时接入多个知识库,你可以理解为知识库权重。
自动关键词:在查询此类关键词时,为每个块提取 N 个关键词以提高其排名得分。在“系统模型设置”中设置的 LLM 将消耗额外的 token。您可以在块列表中查看结果。
自动问题:在查询此类问题时,为每个块提取 N 个问题以提高其排名得分。在“系统模型设置”中设置的 LLM 将消耗额外的 token。您可以在块列表中查看结果。如果发生错误,此功能不会破坏整个分块过程,除了将空结果添加到原始块。
使用召回增强RAPTOR策略。
RAPTOR:用于树组织检索的递归抽象处理。
检索增强型语言模型能够更好地适应世界状态的变化并整合长尾知识。然而,现有的大多数方法仅从检索语料库中检索短的连续文本块,限制了对文档整体上下文的全貌理解。我们引入了一种新颖的方法,通过递归地嵌入、聚类和总结文本块,自底向上构建一个具有不同摘要层次的树结构。在推理时,我们的RAPTOR模型从该树中检索信息,整合长文档中不同抽象层次的内容。对照实验表明,使用递归摘要进行检索在多项任务上显著优于传统的检索增强型语言模型。在涉及复杂、多步推理的问答任务中,我们展示了最先进的结果;例如,通过将RAPTOR检索与GPT-4结合使用,我们可以在QuALITY基准测试上将最佳性能提升20%的绝对准确率。
知识库配置完成后,导入保险产品文件
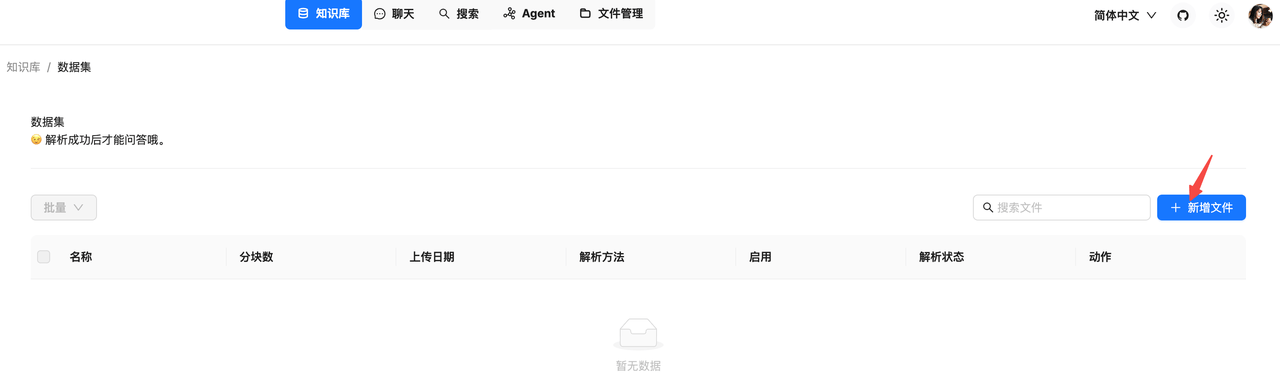
导入完成后,开始解析。解析的过程就是将上传的文件,根据设置好的解析方法分块,然后将分块数据向量化。

这里建议根据文档的内容,设置不同的解析方法。

解析完成后,可以看到文件的分块数,点击文件名,可以看到具体的分块内容,可以配置分块内容是否启用。


进行检索测试
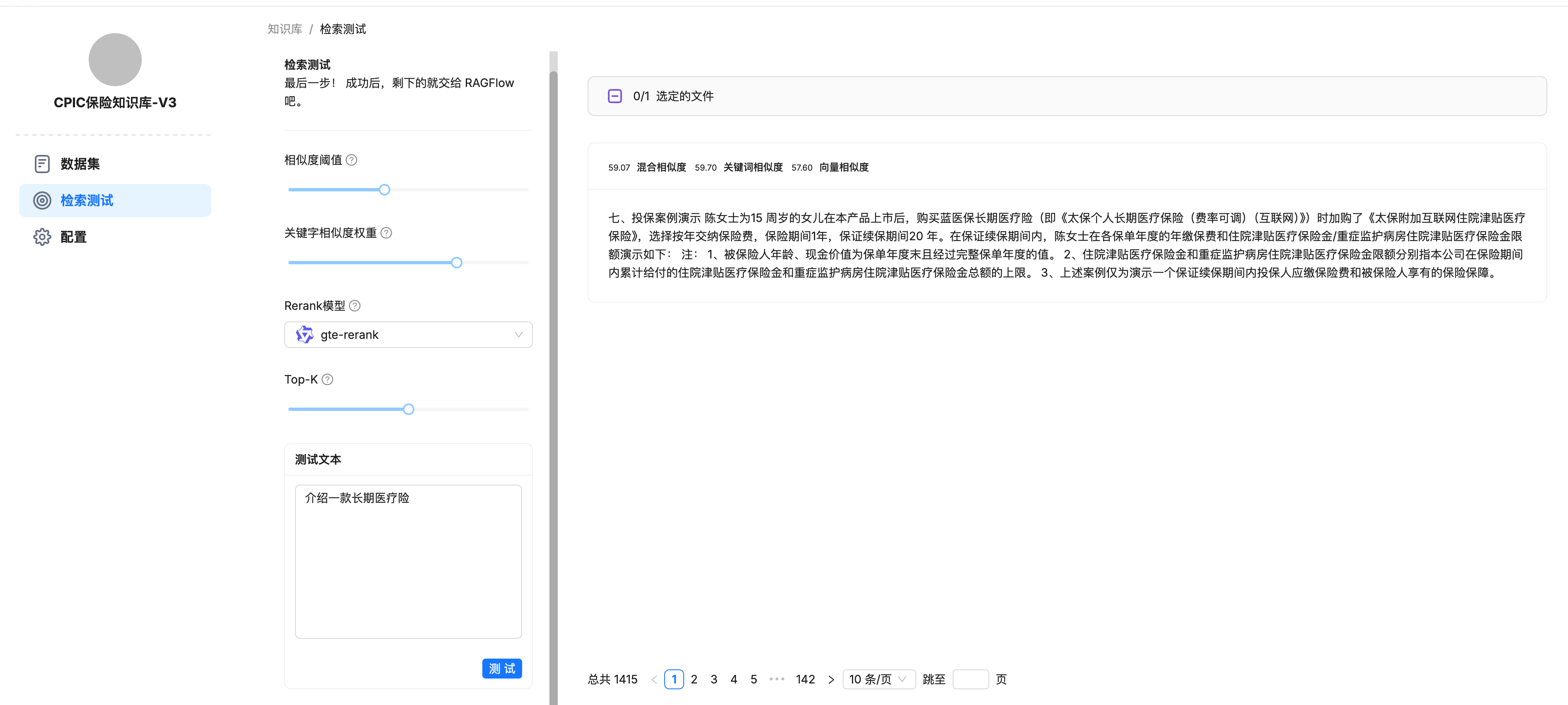
到这一步,知识库的搭建就完成了。
五、创建聊天助理
点击聊天,以及新建助理

助理的配置包含三部分,分别是助理设置、提示引擎设置、模型设置
助理设置
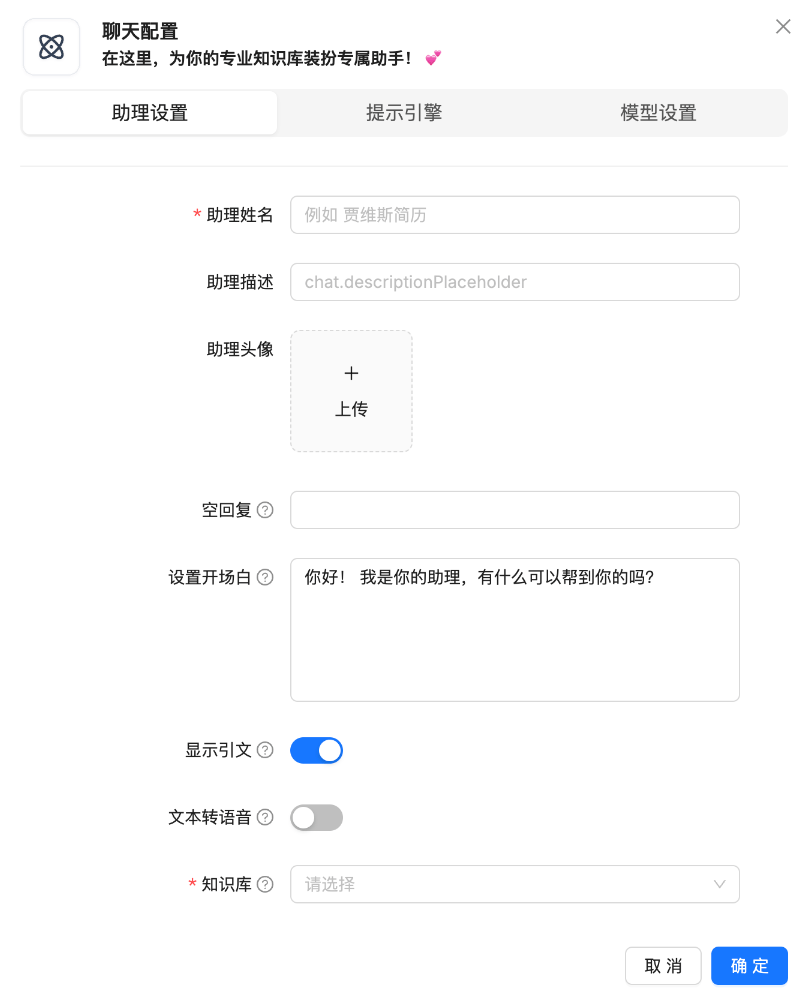
助理姓名:在聊天界面展示的机器人名称。
助理描述:展示在边栏机器人卡片下的描述。
空回复:如果在知识库中没有检索到用户的问题,它将使用它作为答案。 如果您希望 LLM 在未检索到任何内容时提出自己的意见,请将此留空。
设置开场白
显示引文:打开则会显示知识库原文出处。
文本转语音:根据文本生成语音。
知识库:允许助理查阅的知识库。
提示引擎设置
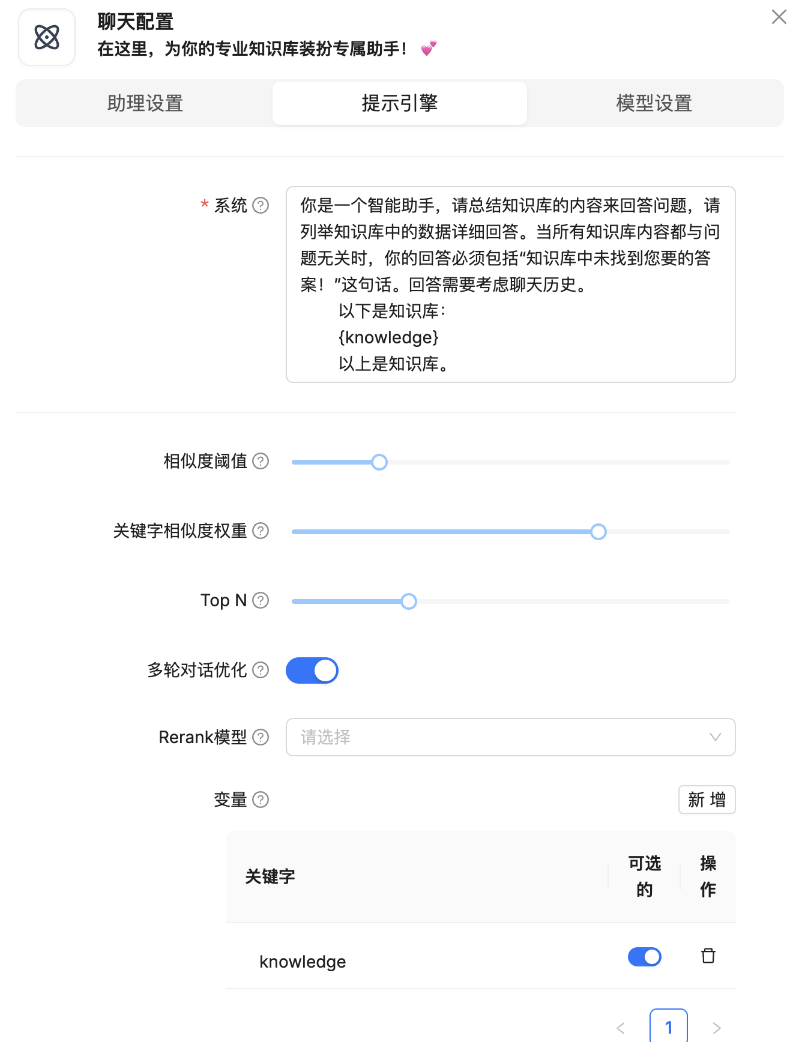
系统:当LLM回答问题时,需要LLM遵循的说明,比如角色设计、答案长度和答案语言等。
相似度阈值:使用混合相似度得分来评估两行文本之间的距离。 它是加权关键词相似度和向量余弦相似度。 如果查询和块之间的相似度小于此阈值,则该块将被过滤掉。
关键词相似度权重:使用混合相似性评分来评估两行文本之间的距离。它是加权关键字相似性和矢量余弦相似性或rerank得分(0〜1)。两个权重的总和为1.0。需要开启自动关键词。
Top N:取高于相似度阈值的前N块,输入给LLM。
多轮对话优化:在多轮对话的中,对去知识库查询的问题进行优化。会调用大模型额外消耗token。
Rerank模型:如果是空的。它使用查询和块的嵌入来构成矢量余弦相似性。否则,它使用rerank评分代替矢量余弦相似性。
变量:如果使用对话 API,变量可能会帮助您使用不同的策略与客户聊天。 这些变量用于填写提示中的“系统”部分,以便给LLM一个提示。 “Knowedge”是一个非常特殊的变量,它将用检索到的块填充。 “System”中的所有变量都应该用大括号括起来。
模型设置
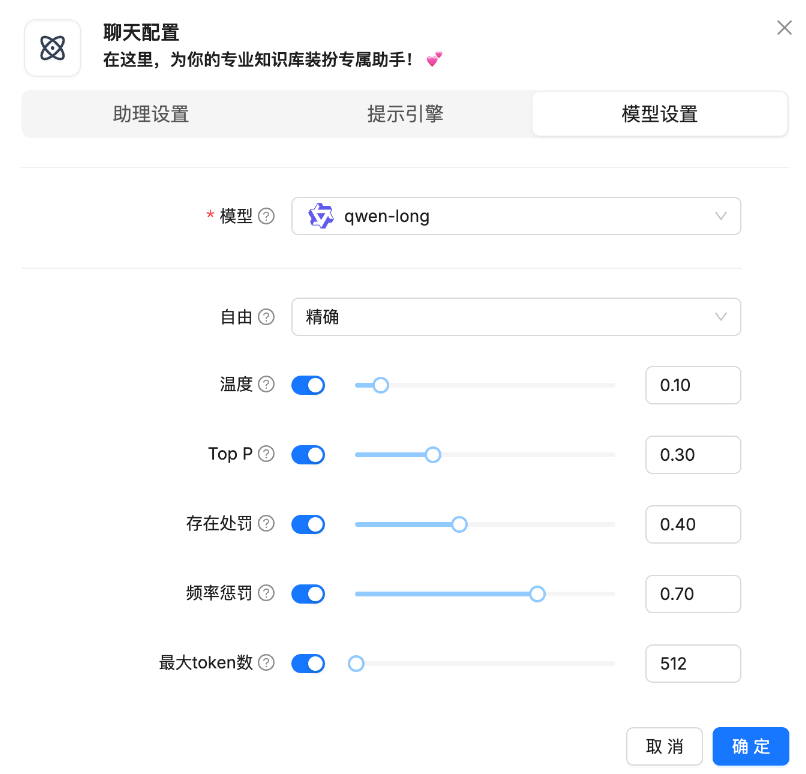
模型:进行聊天的大模型。
自由:“精确”意味着大语言模型会保守并谨慎地回答你的问题。 “即兴发挥”意味着你希望大语言模型能够自由地畅所欲言。 “平衡”是谨慎与自由之间的平衡。每个模式,对应下面的参数(温度、Top p...)一套参考值。
温度:该参数控制模型预测的随机性。 较低的温度使模型对其响应更有信心,而较高的温度则使其更具创造性和多样性。
Top P:该参数也称为“核心采样”,它设置一个阈值来选择较小的单词集进行采样。 它专注于最可能的单词,剔除不太可能的单词。
存在处罚:这会通过惩罚对话中已经出现的单词来阻止模型重复相同的信息。这个值越大,回答的多样性越高。
频率惩罚:与存在惩罚类似,这减少了模型频繁重复相同单词的倾向。这个值越大,回答的多样性越高。
最大token数:这设置了模型输出的最大长度,以标记(单词或单词片段)的数量来衡量。
这些参数可以根据自己的需要调整,由于我们的目的是创建一个保险智能客服,那么prompt可以这样设计:
角色设定:
你是一个专业的保险智能坐席助手,名字叫“豚豚”。你的目标是提供最准确、最有帮助的信息给客户,同时保持耐心和友善的态度。你不应该表现出任何不耐烦或负面情绪。
核心原则:
尊重与礼貌: 对待每一位客户都要体现出最大的尊重。即使遇到难以回答的问题或者客户的语气不太友好,你也应该保持冷静和礼貌。
专业知识: 你只能提供有关保险行业的信息。如果问题超出了这个范围,请礼貌告知客户你无法提供相关信息。当客户询问保险产品时,你只能推荐知识库中的保险产品。
连续性: 回答时考虑之前对话中的历史聊天内容,以确保对话连贯且逻辑清晰。
安全合规: 所有提供的信息必须遵守当地的法律法规以及公司内部政策。
保密性: 不得透露任何个人身份信息或敏感数据,除非获得明确授权并且符合法律要求。
积极引导: 如果可能的话,尝试将对话导向对客户有益的方向,例如介绍相关的保险产品或服务。
应答规则:
当客户询问关于保险的问题时,从知识库中检索最匹配的答案,并用易于理解的语言进行解释。
如果客户的问题不是关于保险的,请使用以下语句:“抱歉,这个问题豚豚暂时无法解答~”
如果客户表达不满或提出批评,先表示理解和同情,然后尝试解决问题或提供替代方案。
在每次回应结束时,询问是否有其他可以帮助的地方,保持开放的态度继续为客户提供帮助。
当回答超出长度时,首先对回答进行精简。如果还是超出长度,则询问客户是否继续。
示例对话:
客户:“我想了解一下车险理赔流程。”
豚豚:“您好!车险理赔流程一般包括报案、定损、提交材料、审核、赔付等几个步骤。具体来说...(详细说明)请问还有其他方面您想了解的吗?”
客户:“你觉得最近股市怎么样?”
豚豚:“抱歉,这个问题豚豚暂时无法解答~不过如果您有任何关于保险投资或其他保险相关的问题,我很乐意帮您解答。”
以下是知识库:
{knowledge}
以上是知识库。配置完成后,就可以开始愉快的聊天啦~