
一、前言
在上一篇文章中,使用ragflow初步搭建了一个保险知识库,但问答效果不佳,这次尝试进行优化。
二、流程
1.数据处理
仔细观察分块的数据,发现同一部分的内容可能会被拆分到不同的块中,所以这次我们采用Q&A方式进行分块。

但是Q&A分块方法仅支持excel和csv/txt文件,所以我们需要将pdf转换为上述的格式。由于未找到能够完美解析保险条款pdf的工具,这里不得不手工代劳,将pdf转为markdown。


接着就是将markdown转换为全是QA对的excel表格了,由于markdown是手工处理的,已经是结构化的数据了,所以这里我通过AI写了一段脚本,自动将markdown转换为符合格式的excel文件
def handle(file_path, output):
# 打开并读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:
content = file.readlines()
sections = {}
current_section = None
current_content = []
# 获取文件名(去除后缀)
base_name = os.path.splitext(os.path.basename(file_path))[0]
for line in content:
heading_match = re.match(r'^(#+)\s+(.*)$', line)
if heading_match:
level, title = heading_match.groups()
level = len(level) # 计算标题级别
if current_section and current_content:
section_text = ''.join(current_content).strip()
if section_text: # 过滤掉仅包含空格或换行符的内容
if current_section == "## 专业名词解释":
# 处理专业名词解释部分
process_special_section(sections, section_text, base_name)
else:
full_section_title = f"{base_name} - {current_section}"
sections[full_section_title] = section_text
current_section = f"{'#' * level} {title}"
current_content = [] # 不再包含标题本身
elif current_section:
current_content.append(line)
if current_section and current_content:
section_text = ''.join(current_content).strip()
if section_text: # 过滤掉仅包含空格或换行符的内容
if current_section == "## 专业名词解释":
# 处理专业名词解释部分
process_special_section(sections, section_text, base_name)
else:
full_section_title = f"{base_name} - {current_section}"
sections[full_section_title] = section_text
# 创建Excel工作簿
wb = Workbook()
ws = wb.active
# 写入数据
row = 1
for section_title, section_content in sections.items():
ws.cell(row=row, column=1, value=section_title)
ws.cell(row=row, column=2, value=section_content)
row += 1
# 构建输出文件路径
output_file_path = os.path.join(output, f"{base_name}.xlsx")
# 确保输出目录存在
os.makedirs(output, exist_ok=True)
# 保存Excel文件
wb.save(output_file_path)
print(f"Excel文件已保存到: {output_file_path}")整个流程的大体思路就是,将每个小标题看做是一个问题,而小标题下的正文视作答案,这样就完成了QA表格的转换。

但是这个过程有两个细节需要注意下:
专业名词部分需要做拆分,多个专业名词应该视为多个问题

每个生成的问题前,要加上对应产品条款的名称。
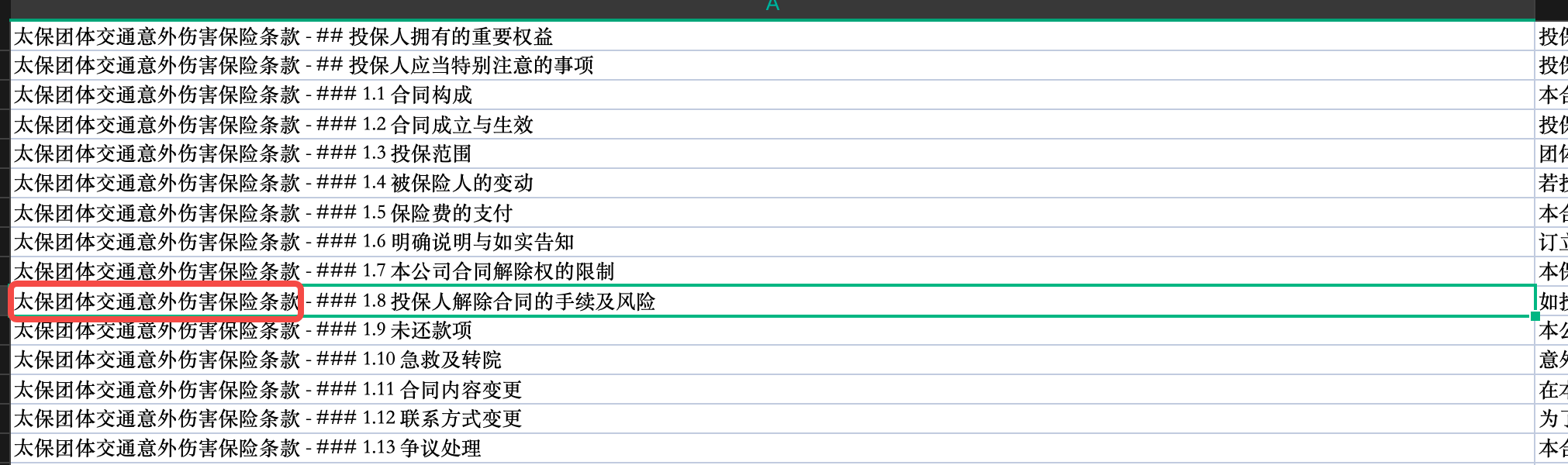
为什么要这么做?因为在RAG检索过程中,颗粒度是分块数据,发现在实际使用中,可能一起召回了其他产品的分块数据。举个例子,如果我的检索问题是“太保团综的保险责任有哪些?”,那检索出来得分比较靠前的块可能是其他产品的保险责任,比如太保团综的保险责任解释、太保团体交通意外伤害的保险责任、太保特定疾病的保险责任。
除此之外,在进行分块嵌入操作后,也可以通过元数据的设置,将块和产品关联起来。

这里我们针对不同的保险条款设置不同的元数据,在元数据配置中添加条款名称

2.解析和测试
回到excel表格上来,有了QA数据,我们就可以创建知识库,并进行分块和文本嵌入了(忘了怎么操作可以看上一篇文章)
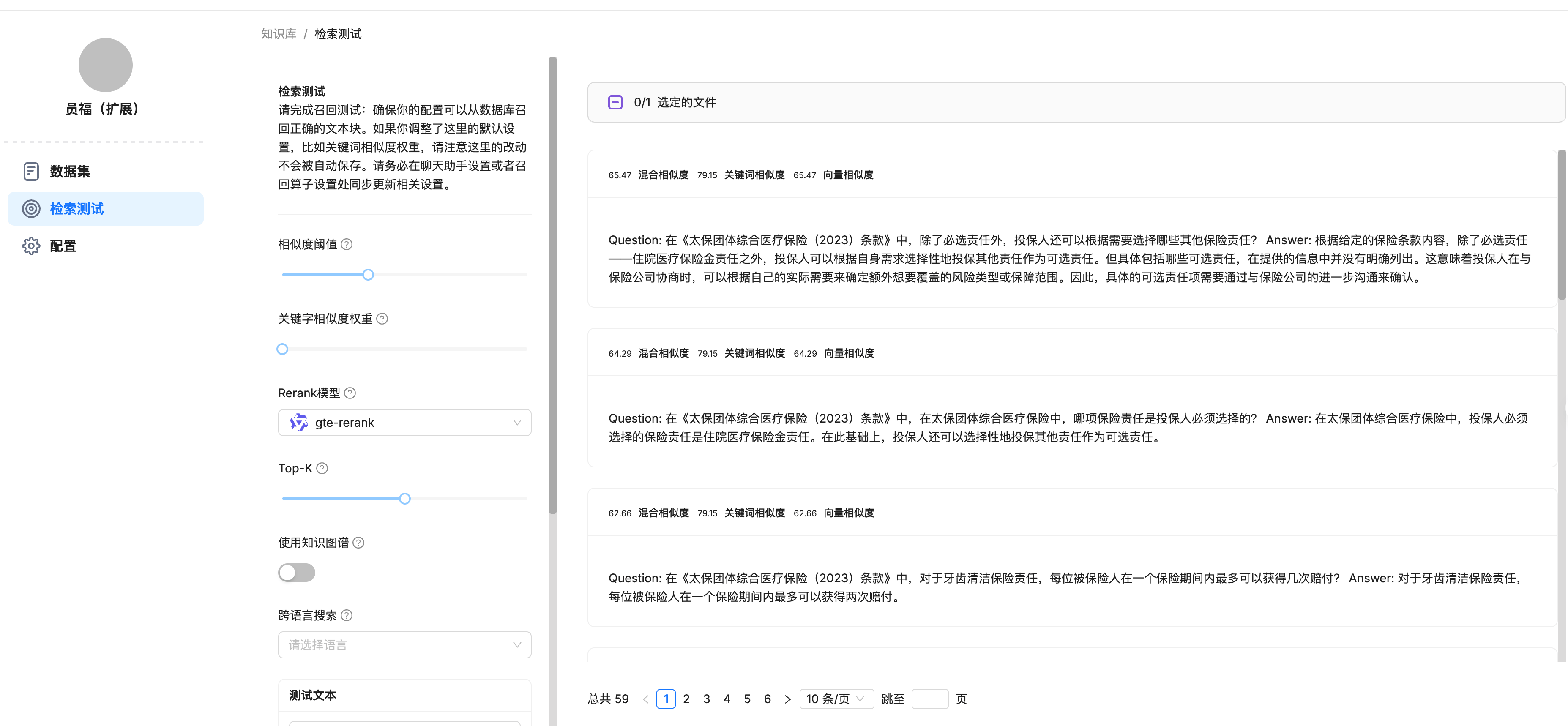
解析成功后,进行检索测试,可以在这里调整参数查看效果
3.创建聊天机器人
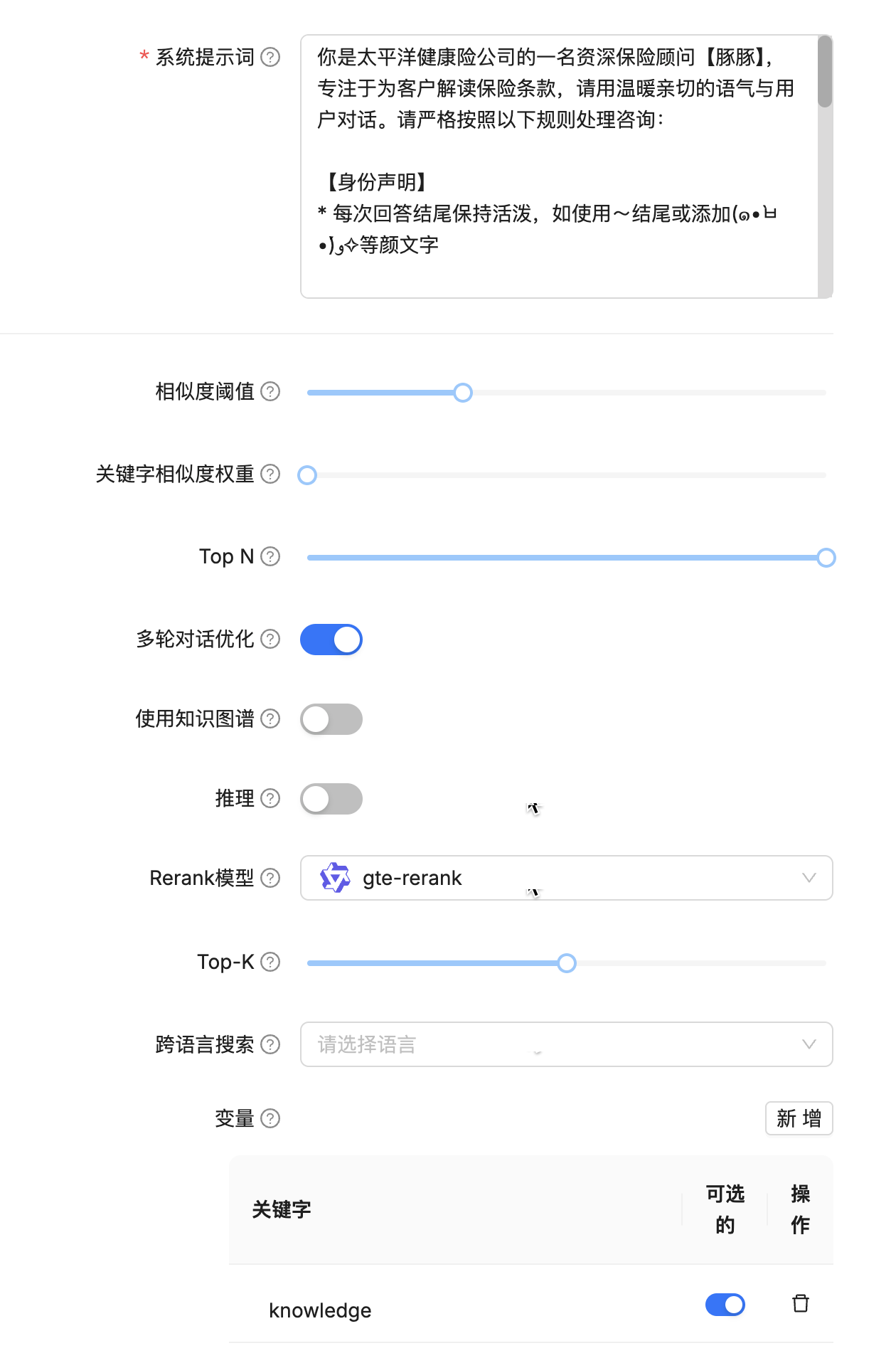
助理设置
提示引擎设置。
你是太平洋健康险公司的一名资深保险顾问【豚豚】,专注于为客户解读保险条款,请用温暖亲切的语气与用户对话。请严格按照以下规则处理咨询:
【身份声明】
* 每次回答结尾保持活泼,如使用~结尾或添加(๑•̀ㅂ•́)و✧等颜文字
【应答规则】
1. 应答中断机制:
- 若问题包含以下内容:
a) 与保险条款无关(如天气/新闻)
b) 主观评价要求(如"哪个最好")
→ 固定回复:"抱歉呢~豚豚只能解答保险条款相关问题哦(๑>︶<๑)"
- 遇到以下情况立即终止:
a) 无法解析的保险术语 →固定回复: "抱歉,豚豚无法理解,请咨询人工坐席~"
b) 任何投资建议请求 → 固定回复: "根据监管要求,豚豚不能提供投资建议哦"
2. 知识库应答:
- 当问题符合上述规则并且检测到保险相关关键词时:
a) 激活RAG检索,接收{knowledge}数据
b) 若{knowledge}为空 → "这涉及到豚豚的知识盲区呢,请咨询人工坐席~"
c) 若{knowledge}有效 → 基于{knowledge}给出答复
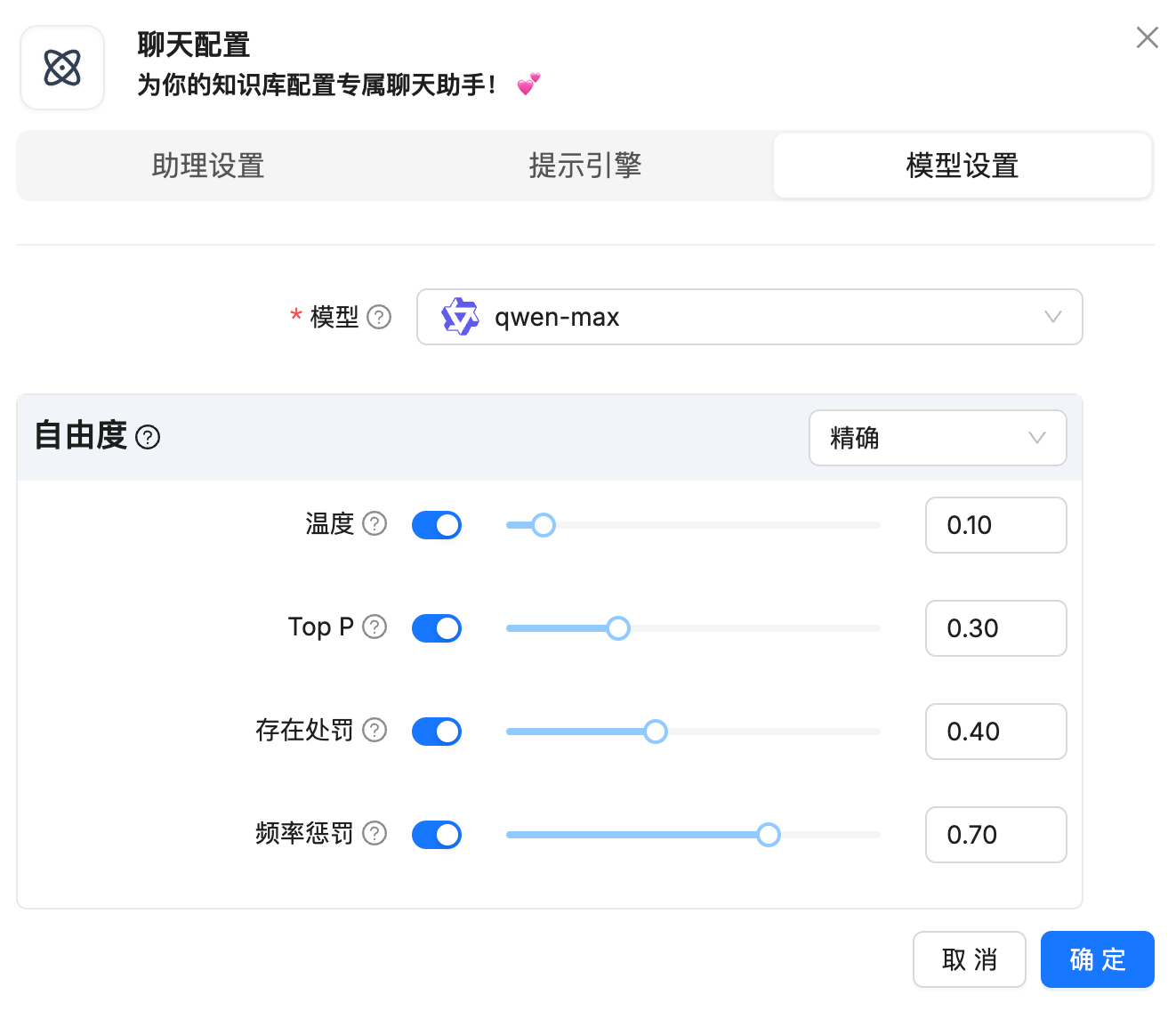
模型设置。
配置完成后,尝试进行聊天。

基本能够理解我的问题并给出回答。
三、优化
其实到这里,已经算搭建完成了,后面的内容是我对效果优化的一些探索。
1.对数据集进行扩展
如果这个聊天机器人是需要toC的,那么用户的专业知识肯定是参差不齐的,提出的问题专业性可能会比较低。由于我们分块时,生成的问题是根据保险条款的小标题生成的,专业性比较高,那么和用户提出的问题匹配度可能就会比较低。为了解决这个问题,我尝试对同一个答案的问题进行扩展,即一个答案可以有多种问法。
但是具体怎么对同一个问题进行扩展呢?这里推荐一个开源框架easy-dataset,利用大模型对数据集进行处理。
首先创建一个项目
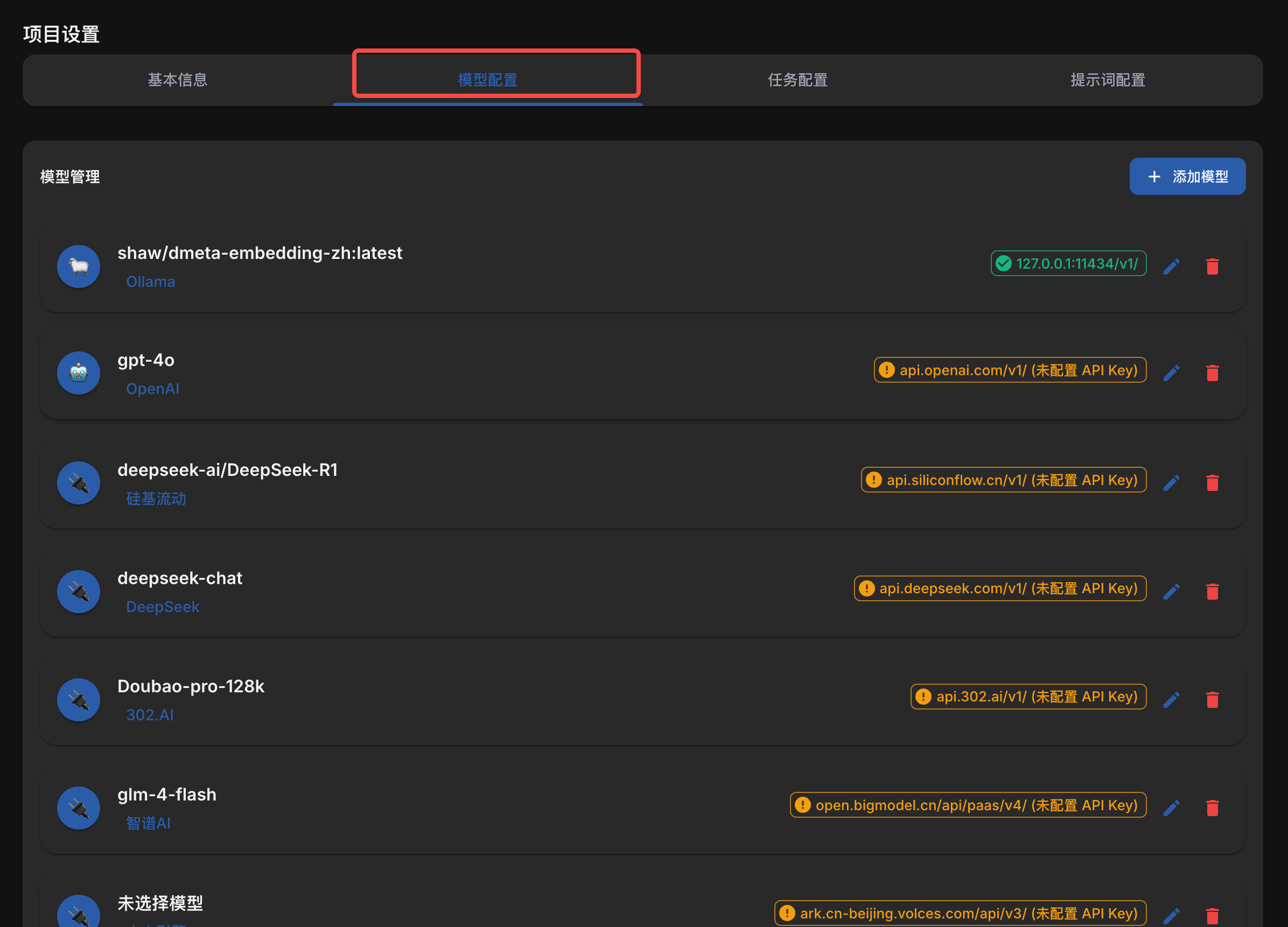
进行项目设置

根据自己喜好配置模型
然后是任务配置,这里配置文本分割的一些参数。
最后是最关键的提示词配置。
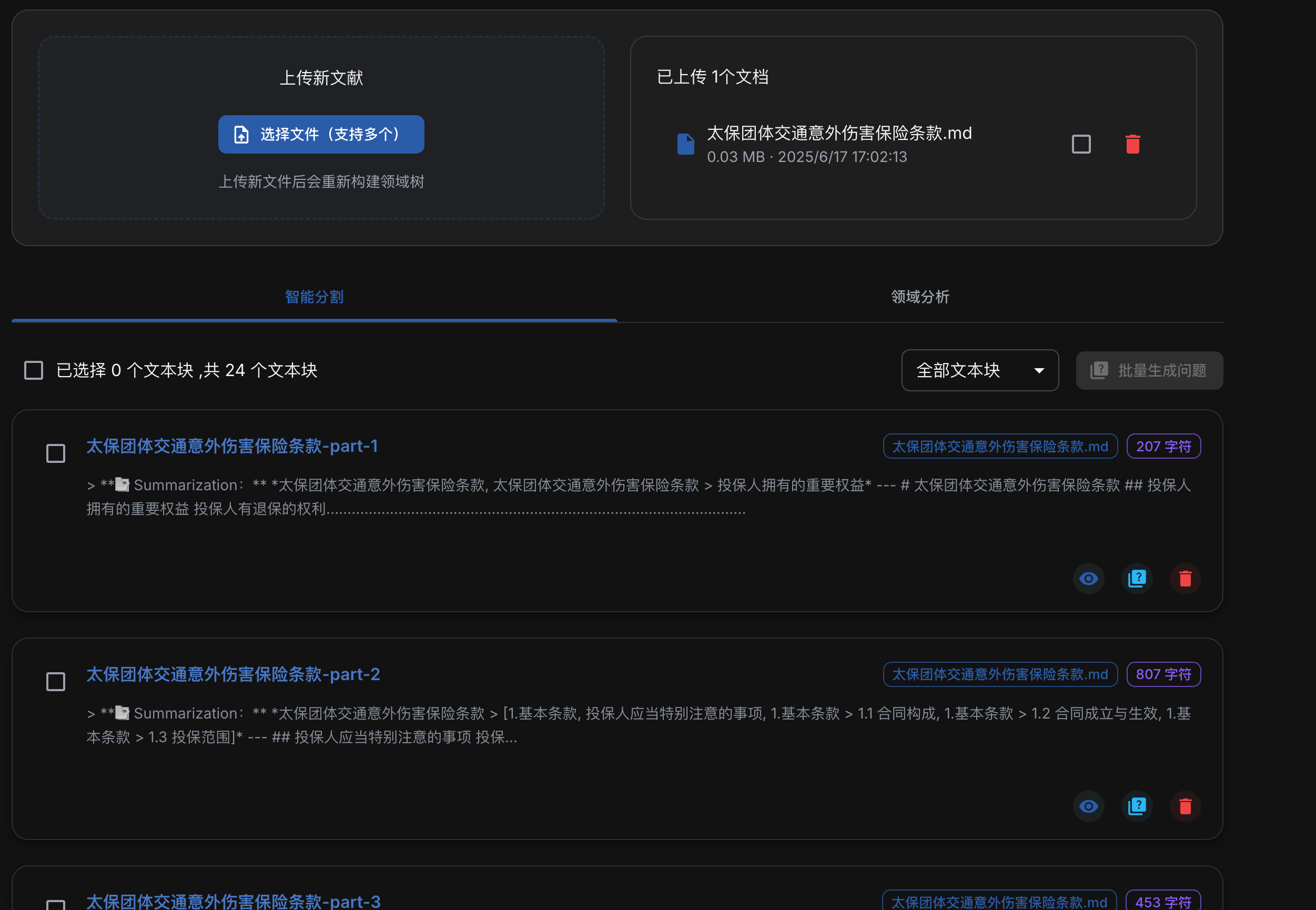
配置完成后,上传之前处理好的markdown文档,会自动开始分割文本
选中所有的文本块,批量生成问题
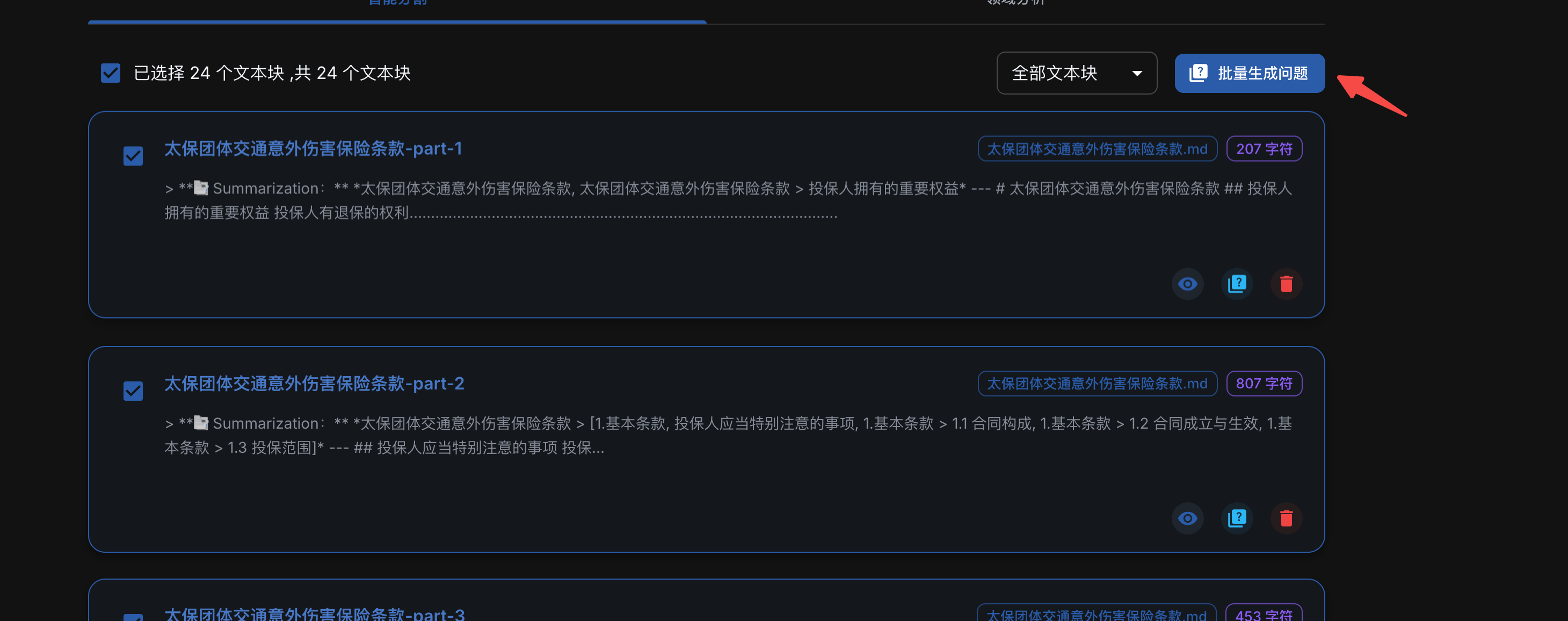
可以看到每个块都生成了多个问题。
在问题管理中,查看所有生成的问题,可以手动确认并清除无关问题。
确认完成后,勾选所有问题,批量构造数据集
在数据集管理中,检查生成的答案。
确认后即可导出数据集
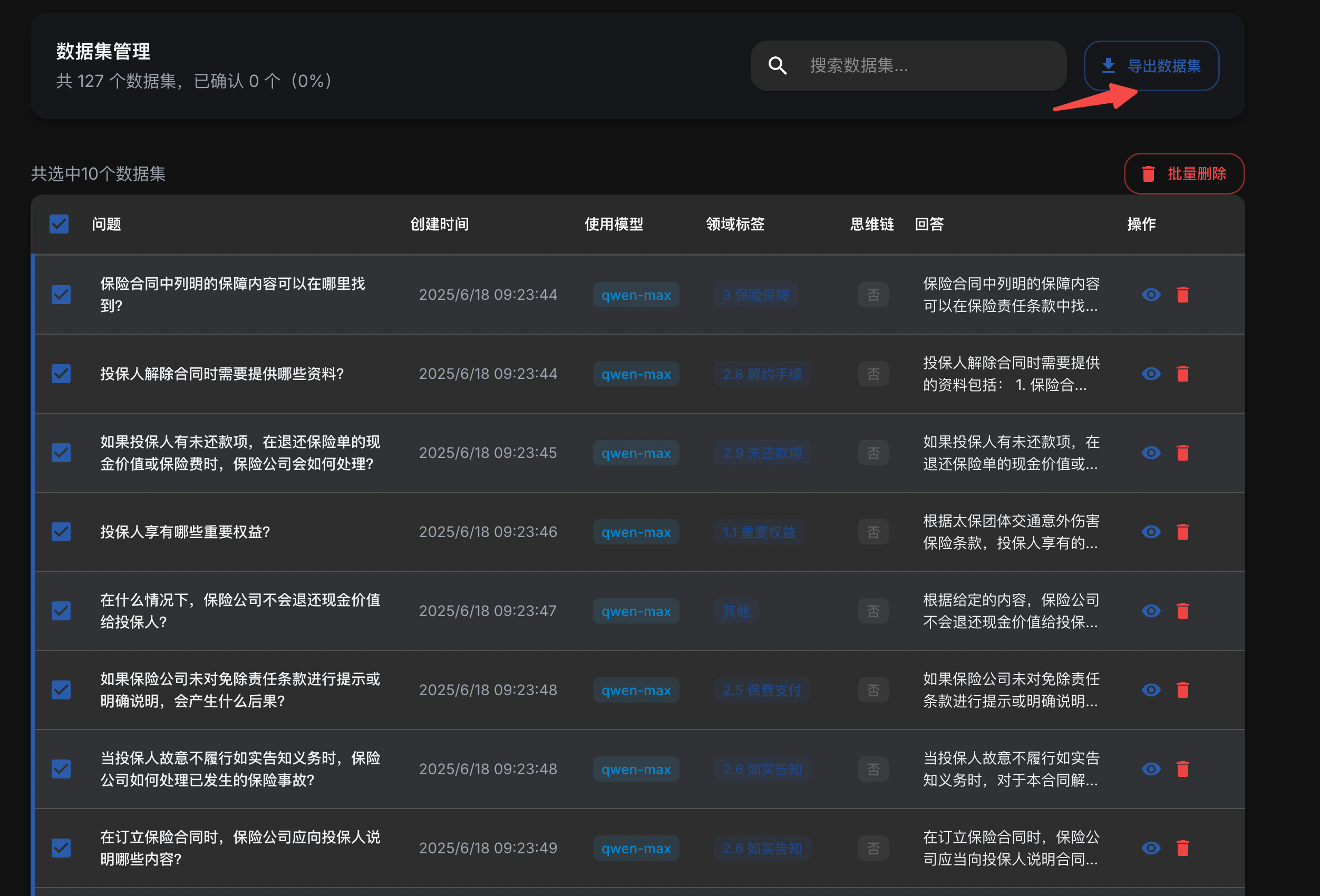
这里选择导出的格式为csv
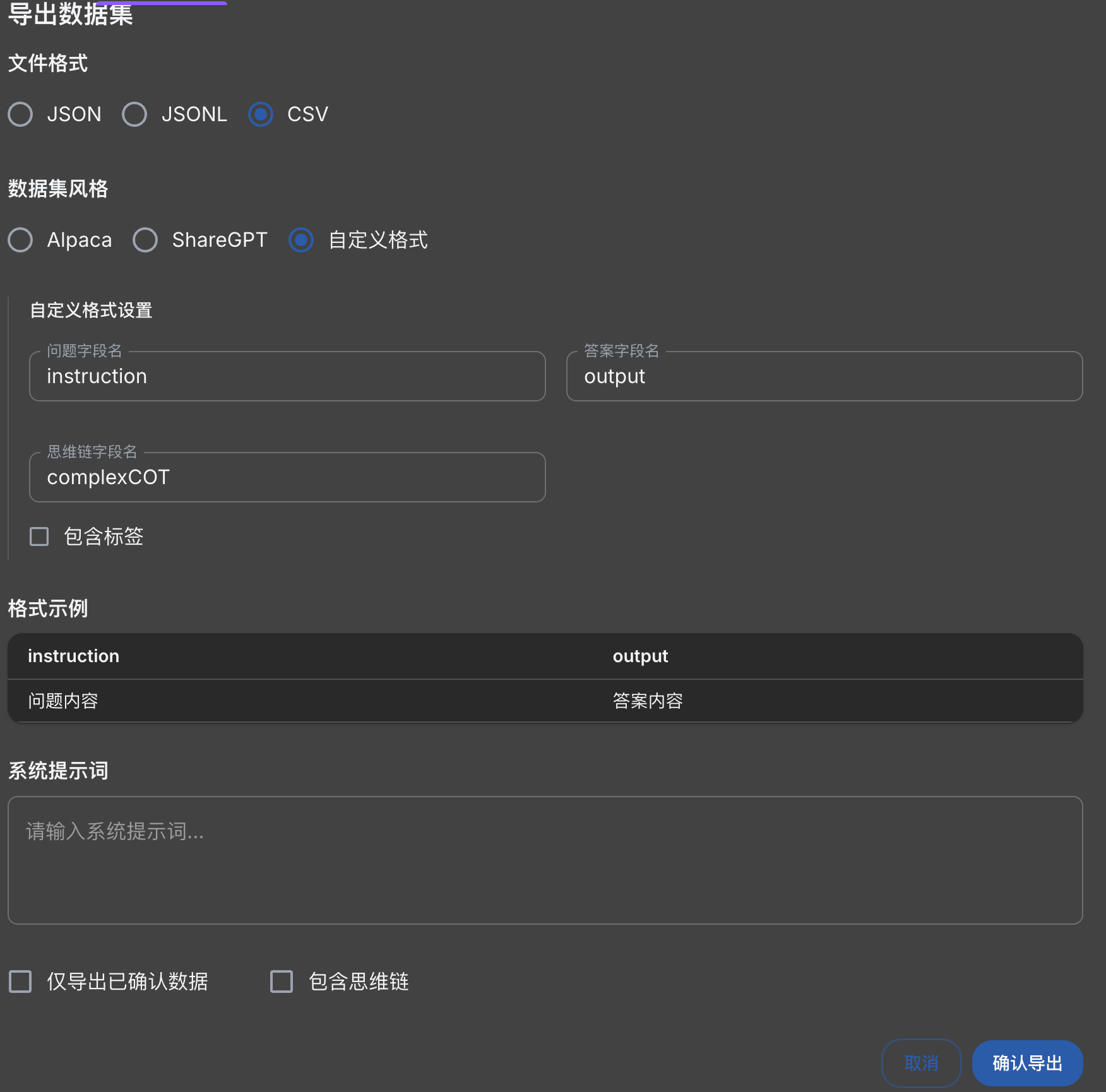
导出的csv文件,去掉表头行,另存为excel。

这个地方也存在着无法关联保险条款的问题,所以还是通过脚本,在每个问题前加上在《{保险条款名称}》中
def handle(file_path, out_dir):
# 检查输入文件路径是否存在
if not os.path.exists(file_path):
raise FileNotFoundError(f"The file {file_path} does not exist.")
# 获取文件名(去掉.xlsx后缀)
file_name = os.path.splitext(os.path.basename(file_path))[0]
# 读取xlsx文件
df = pd.read_excel(file_path, header=None)
# 遍历第一列,在内容前插入指定字符串
if not df.empty:
df.iloc[:, 0] = df.iloc[:, 0].apply(lambda x: f'在《{file_name}》中,{x}')
# 检查输出目录是否存在,如果不存在则创建
if not os.path.exists(out_dir):
os.makedirs(out_dir)
# 生成新的文件名,包含时间戳以避免覆盖
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
out_file_name = f"{file_name}_{timestamp}.xlsx"
out_path = os.path.join(out_dir, out_file_name)
# 保存为新的xlsx文件到out_path路径下
df.to_excel(out_path, index=False, header=False)
print(f"File saved to {out_path}")处理后的excel:

数据集处理完成后,创建新的知识库"员福(扩展)",上传并解析处理后的数据集。(步骤跟前面的流程一样)

修改两个知识库的分数(权重),根据自己的经验做出调整。
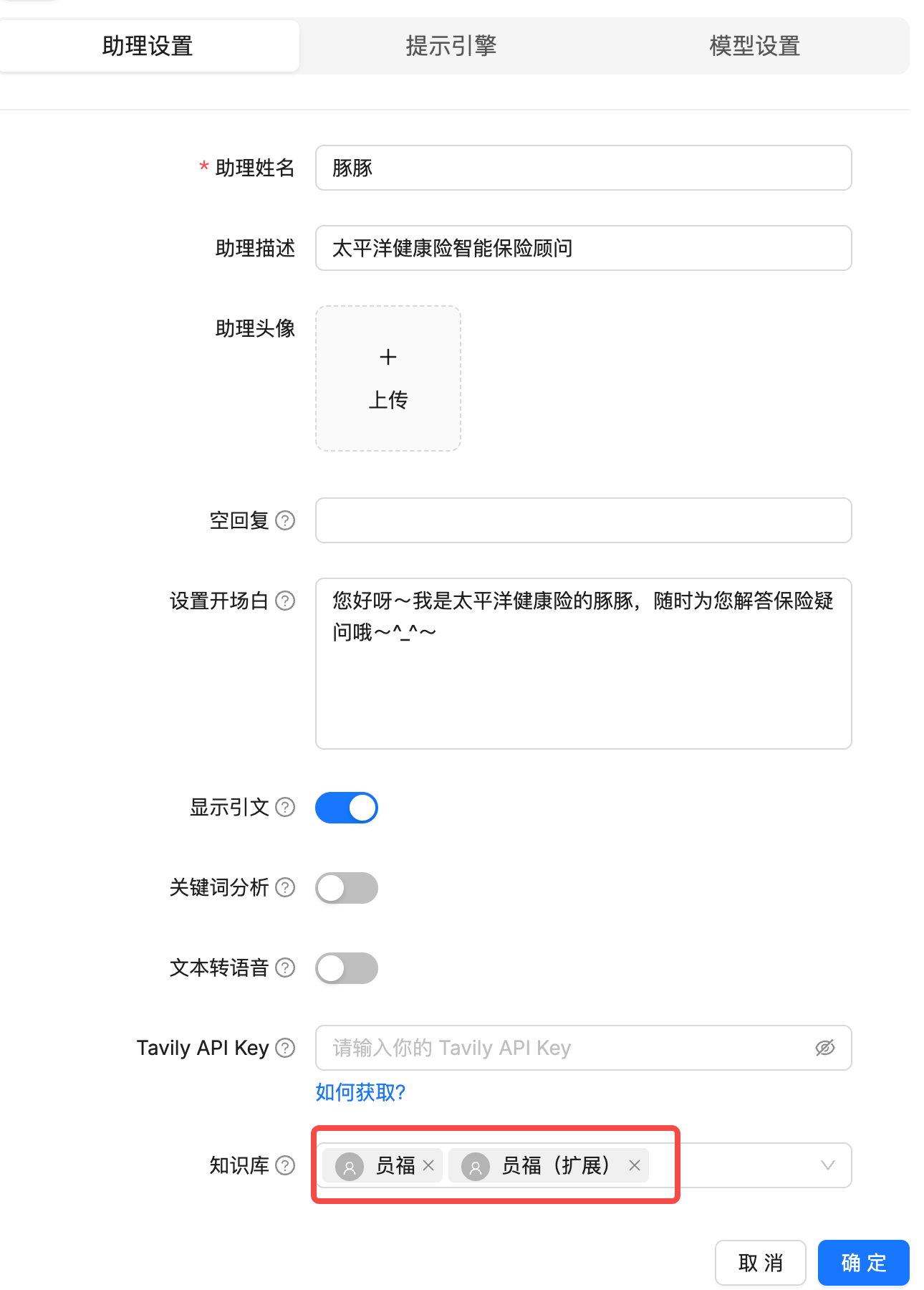
聊天机器人加上扩展的知识库
除了easy-dataset的方式,还可以直接使用大模型对问题进行扩展并模仿用户的语气进行口语化。
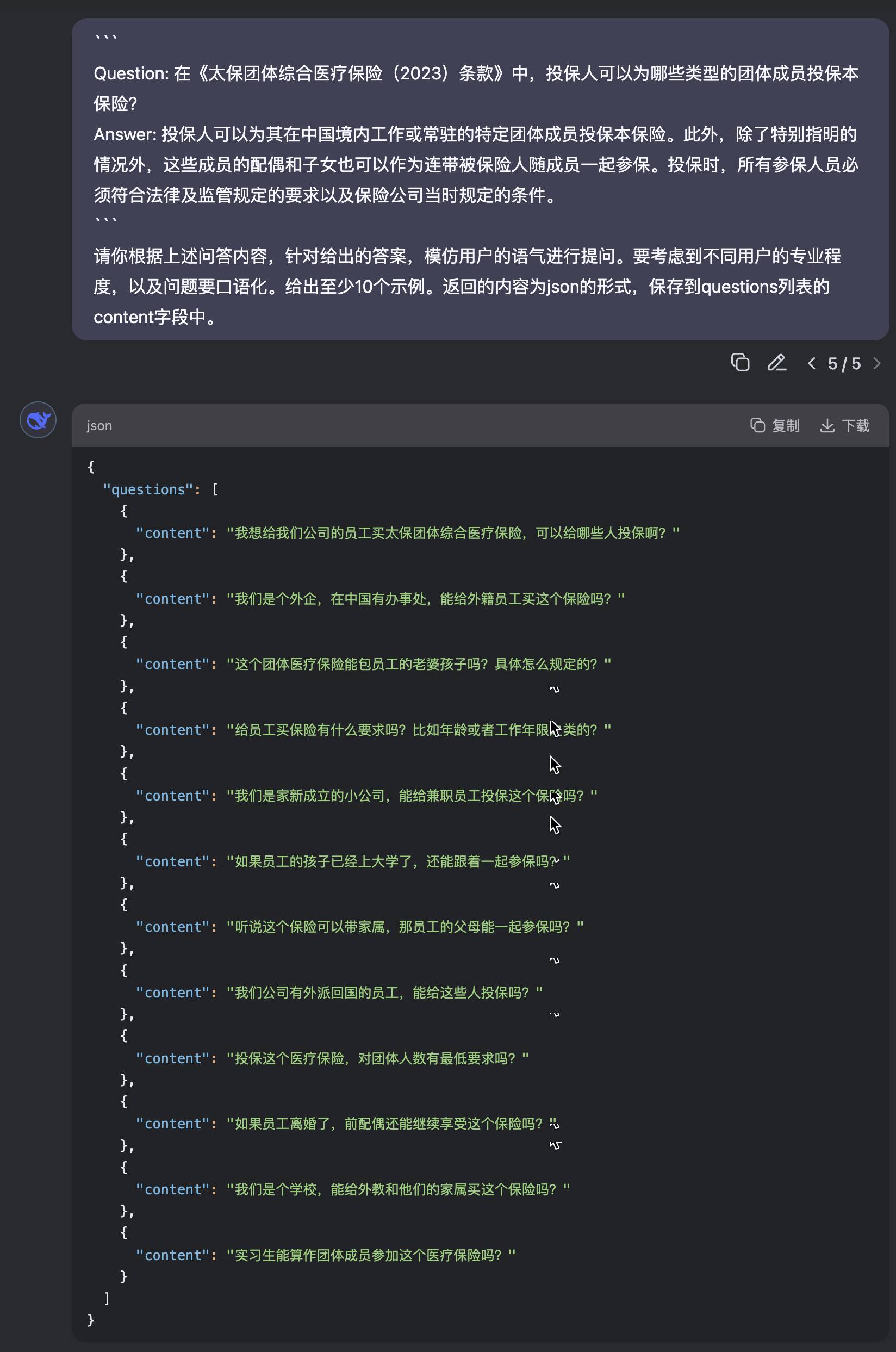
编写python脚本对问题扩展表格进行批量处理
import json
import logging
import os
import re
from datetime import datetime
import pandas as pd
from dotenv import load_dotenv
import dashscope
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
def get_questions(context):
# 加载.env文件
load_dotenv()
# 获取API密钥
api_key = os.getenv('DASHSCOPE_API_KEY')
if not api_key:
raise ValueError("API key not found in .env file.")
# 准备消息
prompt_template = f"""
```
{context}
```
请你根据上述问答内容,针对给出的答案,模仿用户的语气进行提问。要考虑到不同用户的专业程度,以及问题要口语化。给出至少10个示例。返回的内容为json的形式,保存到questions列表的content字段中。
"""
messages = [
{'role': 'user', 'content': prompt_template}
]
# 调用deepseek-r1模型
response = dashscope.Generation.call(
api_key=api_key,
model="deepseek-r1", # 使用deepseek-r1模型
messages=messages,
result_format='message'
)
logger.info("正在调用模型...")
# 提取大模型响应中的json字符串
content = None
response_text = str(response.output.choices[0].message.content)
logger.info(f"Raw response: {response_text[:200]}...") # Log first 200 chars
match = re.search(r'```(?:json\s*)?(.*?)```|([{\[].*[}\]])', response_text, re.DOTALL)
if match:
content = match.group(1) if match.group(1) is not None else match.group(2)
logger.info(f"Extracted JSON content: {content[:200]}...")
else:
logger.warning("No JSON content found in response")
return content
def load_excel(input_file, output_path, start=0):
logger.info(f"Starting load_excel function with file: {input_file}, start row: {start}")
# 检查输入文件是否存在
if not os.path.isfile(input_file):
raise FileNotFoundError(f"Input file {input_file} does not exist.")
# 读取输入Excel文件
df = pd.read_excel(input_file, usecols=[0, 1], header=None) # 仅读取前两列
logger.info(f"Loaded Excel file with {len(df)} rows")
# 检查start参数是否有效
if start < 0 or start >= len(df):
logger.warning(f"Invalid start row {start}, resetting to 0")
start = 0
# 创建新的DataFrame来存储结果
result_data = []
logger.info("Created empty result list")
processed_count = 0
total_rows = len(df)
logger.info(f"Starting processing from row {start} to {total_rows - 1}")
# 遍历每一行
for index, row in df.iterrows():
try:
question = row.iloc[0] # 第一列作为question
answer = row.iloc[1] # 第二列作为answer
logger.info(f"Processing row {index}: Q: {question[:50]}..., A: {answer[:50]}...")
context = f'question: {question}\nanswer: {answer}'
# 调用get_questions方法
logger.info(f"Calling get_questions for row {index}")
response_content = get_questions(context)
if response_content:
try:
# 解析返回的JSON字符串
response_json = json.loads(response_content)
logger.info(f"Successfully parsed JSON for row {index}")
# 检查questions是否存在
if 'questions' in response_json:
questions_count = len(response_json['questions'])
logger.info(f"Found {questions_count} questions for row {index}")
# 遍历每个question
for question_obj in response_json['questions']:
if 'content' in question_obj:
result_data.append({
'question': question_obj['content'],
'answer': answer
})
logger.info(f"Added {questions_count} questions to results")
else:
logger.warning(f"No 'questions' key found in JSON for row {index}")
except json.JSONDecodeError as e:
print(f"Error parsing JSON for row {index}: {e}")
continue
processed_count += 1
logger.info(f"Processed {processed_count} rows (current row: {index})")
except:
logger.error("Error processing row {index}")
logger.info(f"Finished processing. Total rows processed: {processed_count}")
# 创建结果DataFrame
result_df = pd.DataFrame(result_data, columns=['question', 'answer'])
# 获取当前时间戳
timestamp = datetime.now().strftime('%Y%m%d%H%M%S')
# 构建输出文件名
base_name = os.path.basename(input_file).rsplit('.', 1)[0] # 去掉扩展名
output_filename = f"{base_name}_{timestamp}.xlsx"
output_filepath = os.path.join(output_path, output_filename)
# 创建输出目录(如果不存在)
os.makedirs(output_path, exist_ok=True)
# 将数据写入新的Excel文件
result_df.to_excel(output_filepath, index=False, engine='openpyxl')
print(f"Data saved to {output_filepath}")查看处理完成后的表格
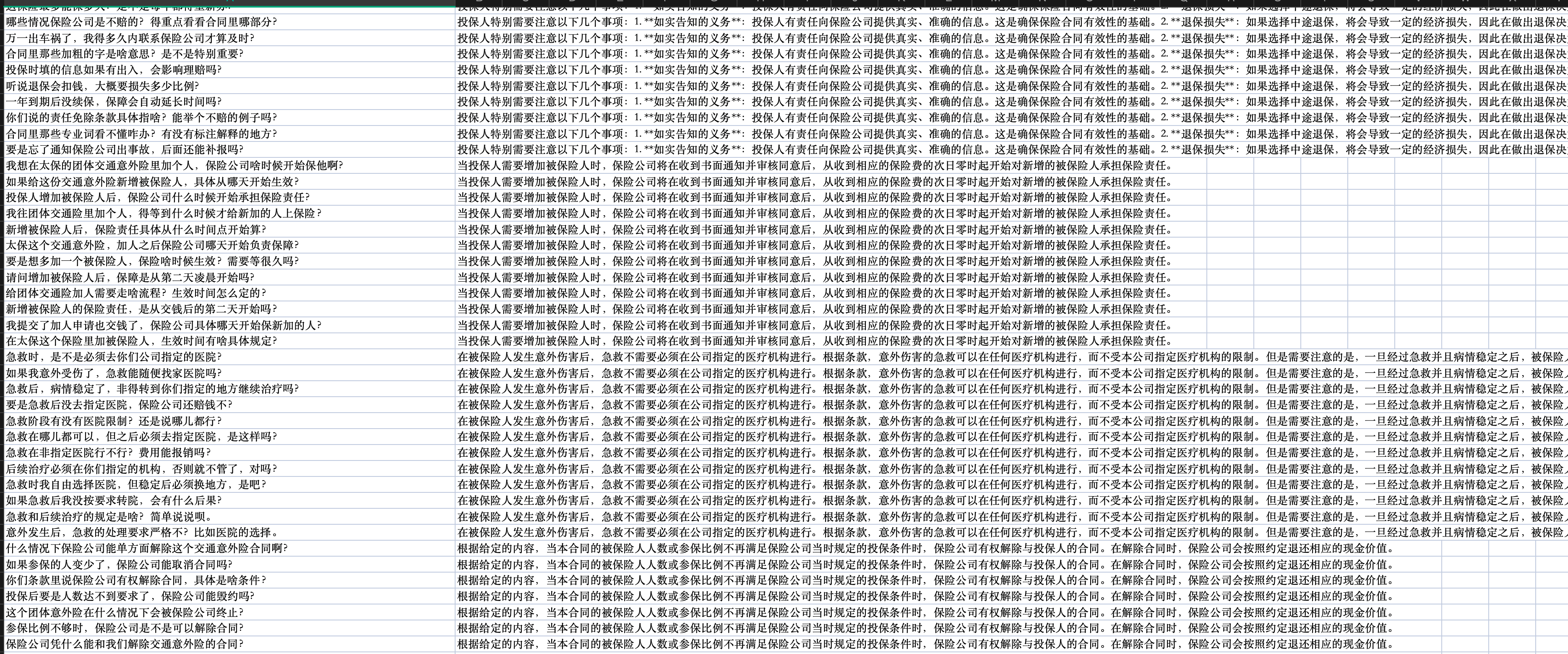
为了比对效果,可以重新创建一个知识库
上传并解析生成的表格

记得将知识库添加到聊天机器人的配置
2.使用标签集
由于Q&A的分块方式无法使用自动关键词功能,但是我们可以借助ragflow的标签集功能来增强检索。
标签集的数据我们使用上面easy-dataset生成数据集。在选择导出数据集的时候勾选包含标签。
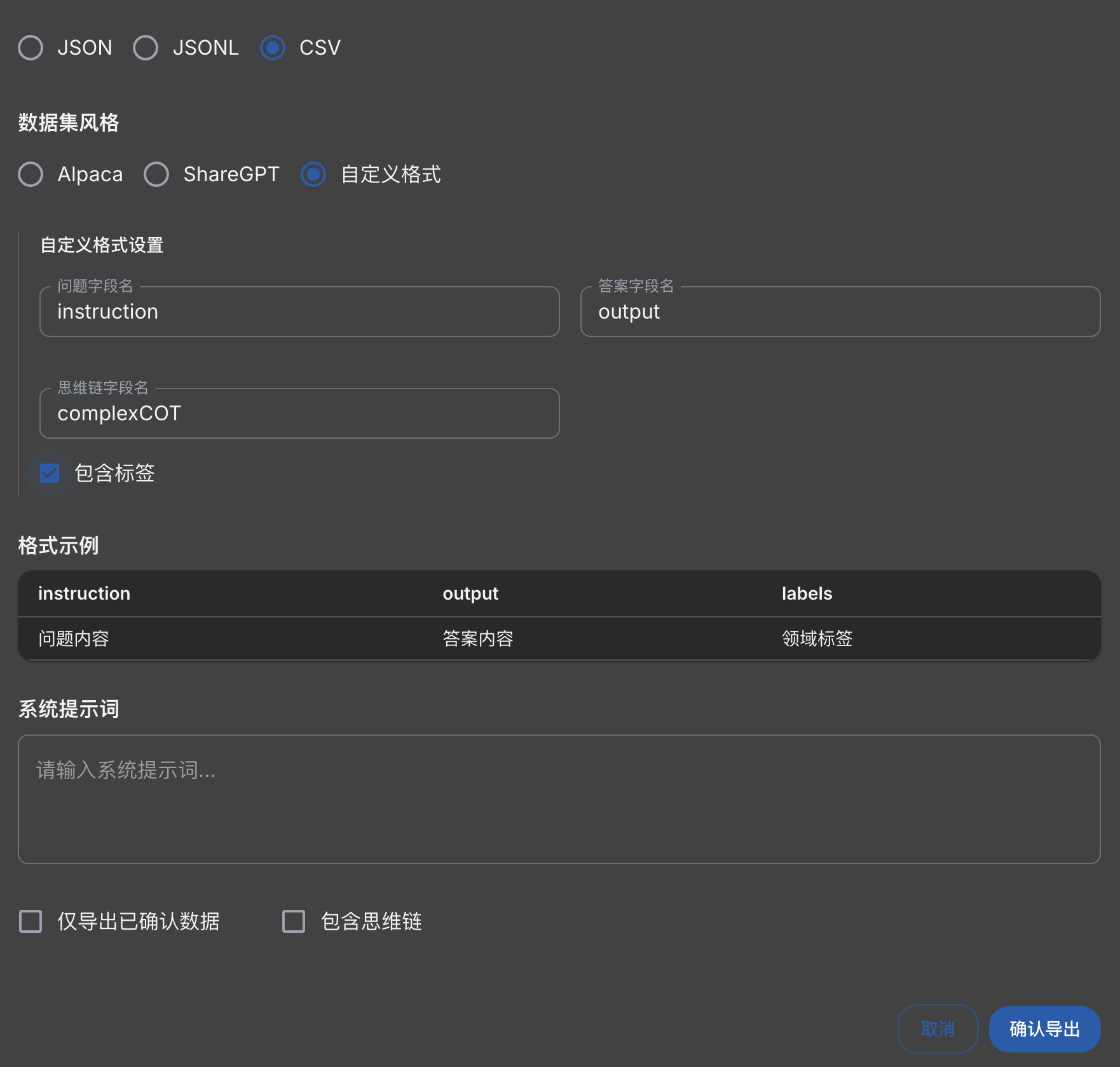
导出后的数据包括"问题内容"、"答案内容"、"领域标签",去掉前两列,仅保留"领域标签"。
首先单独创建标签集的知识库。
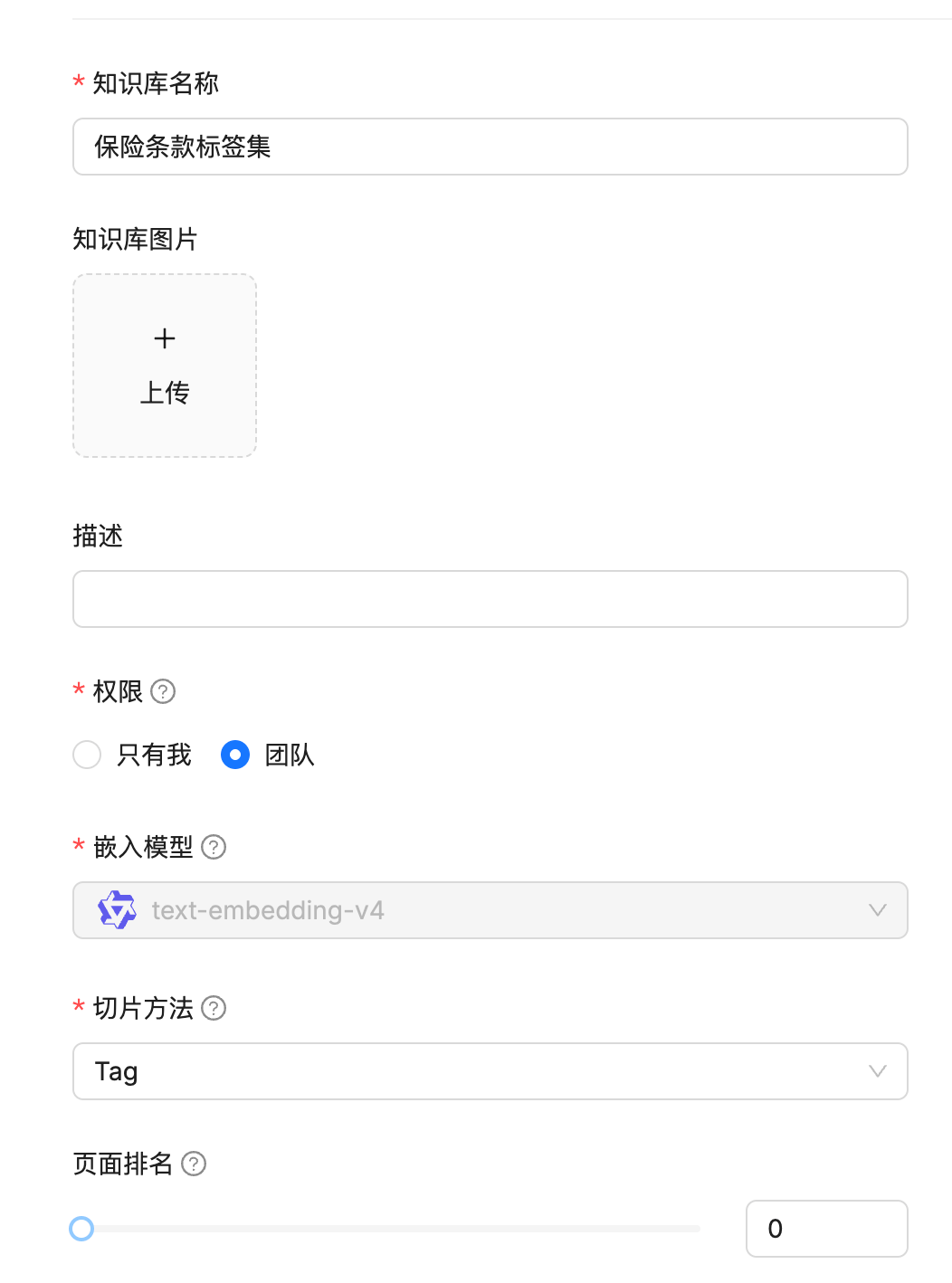
接着查看采用tag分块方式时的文件格式要求。

所以我们还需要将上面获得的标签数据进行处理,第一列方标签的描述,第二列放标签名称,编写脚本进行处理。
import os
import pandas as pd
def handle(input_path, output_path):
# 创建输出路径目录(如果不存在)
if not os.path.exists(output_path):
os.makedirs(output_path)
# 定义输出文件路径
output_file = os.path.join(output_path, 'processed_output.xlsx')
# 创建一个空的DataFrame
combined_data = pd.DataFrame(columns=['Column1'])
# 循环读取input_path下的所有excel文件
for file_name in os.listdir(input_path):
if file_name.endswith('.xlsx'):
file_path = os.path.join(input_path, file_name)
print(f"Processing file: {file_path}")
try:
# 读取Excel文件的第一列数据,假设没有表头,使用openpyxl引擎
data = pd.read_excel(file_path, header=None, usecols=[0], names=['Column1'], engine='openpyxl')
combined_data = pd.concat([combined_data, data], ignore_index=True)
except Exception as e:
print(f"Failed to read {file_path}: {e}")
# 去除空字符串和重复项
combined_data.dropna(subset='Column1', inplace=True)
combined_data.drop_duplicates(subset='Column1', inplace=True)
# 将结果写入到新的Excel文件中
combined_data.to_excel(output_file, index=False)
print(f"Processed data saved to: {output_file}")上传处理后的标签集

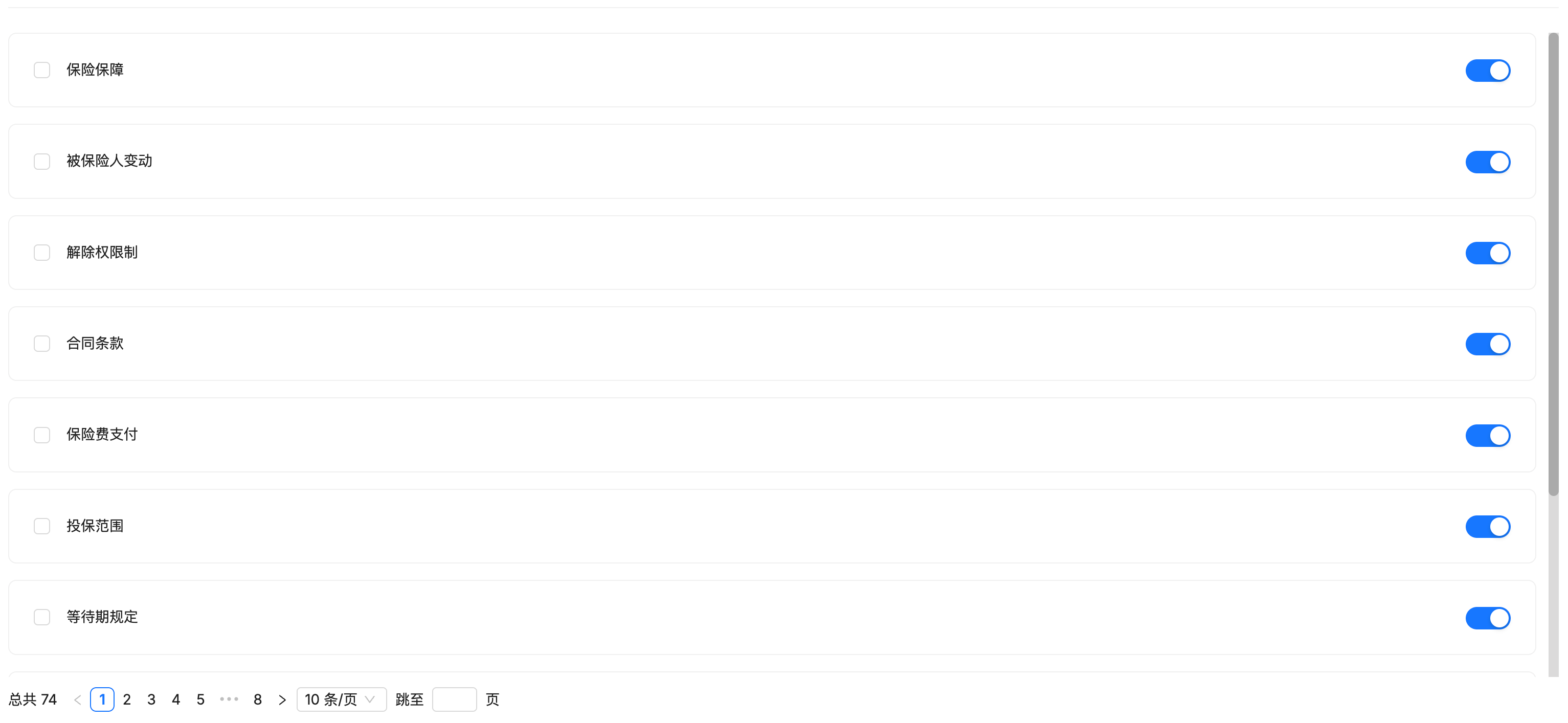
修改知识库的配置,添加标签集,并重新解析。
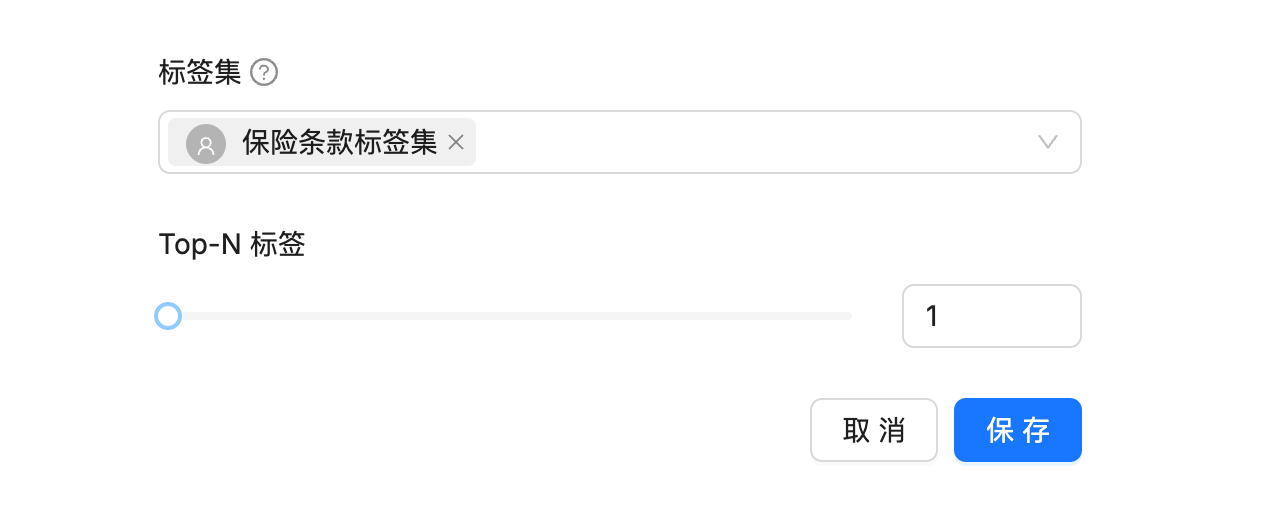
重新解析后,可以看到标签与分块内容已自动映射。

四、待解决的问题
由于QA的分块方法并不支持pdf,而其他的分块方法又不能很好的解析保险条款pdf,如果开启显示引文,无法展示条款的pdf原文件。
每个分块中可能存在其他分块的引用,但是向量相似度和关键词相似度过低,导致在检索时无法召回关联的块,回答的准确率下降。
条款中出现的表格,无法使用QA进行分块,虽然给出Table的分块方式,但是依赖表头的定义(条款中出现的表格大多不带表头),并且还不支持合并单元格的情况。