
一、什么是RAG
RAG(Retrieval-Augmented Generation),即检索增强生成。一句话解释,就是通过在数据中检索出的信息,增强大模型内容生成的一种技术。
二、为什么要使用RAG
我们先来看一个生活中的例子来理解RAG:
假如你现在正在旅游,想要去吃一下当地的特色。
由于你是第一次来这里,你并不知道有哪些选择,于是你打开了小红书、美团、大众点评,查到了一些攻略、评价、价格等信息。
基于你得到的信息,你选择了一家你最想去的餐厅,用餐体验良好,完美避坑。
在这个例子中,根据自己的知识和经验,做出的决策可能很糟糕,于是通过上网搜索的方式,获取到了一些经验信息,基于这些信息,使做出的决策更加有利于达成目标。
在大模型使用场景,其实也存在这个问题,虽然大模型的知识量储备惊人,但是在私域场景下的问答(比如企业内部数据)效果可能不尽人意,因为大模型缺少问答的背景信息。还有就是对最新知识的了解有限。
对于这个问题,一般有两种解决方案。一是对大模型进行微调(Fine-tuning),二就是使用RAG(Retrieval-Augmented Generation)。
模型微调是指在预训练好的大型语言模型基础上,通过引入特定任务的数据集进行进一步训练,以优化模型在该特定任务上的性能。
微调固然效果好,可以让模型真正的“学会”一些私域知识。但是微调也会带来几个问题:首先,由于生成模型依赖于内在知识(权重),因此模型还是无法摆脱幻觉的产生,在对理解门槛高且准确性要求严格的场景下,这就是完全无法接受的,因为用户很难从回答的表面看出模型是否是在胡说八道。其次,在真实场景中,每时每刻都在产生大量数据,对一个事物的概念会迭代的飞快,如某个政策的解读、某个指标的调整等。而模型微调并不是一个简单的工作,无论是从数据准备、算力资源、微调效果、训练时间等各个角度来看,随时用新产生的数据来进行微调都是不现实的,且最终微调的效果也无法保证,能够做到每月更新一次都已经是很理想的状态。所以综合以上考虑,使用RAG与外部信息进行互动是更容易接受的方案。
三、RAG的处理流程
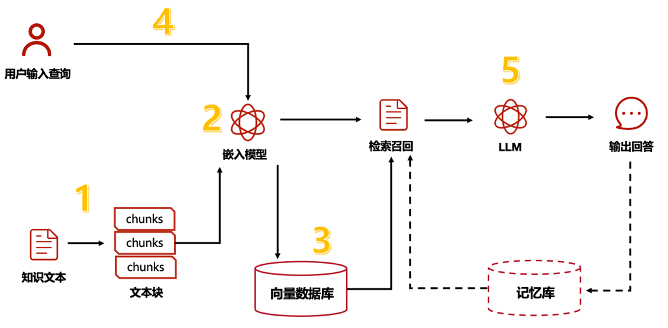
上述过程可以概括为检索、融合、生成。
如果想要使RAG的效果更好,那么就可以在这三个步骤上做扩展:
1.检索的目的是找出与用户提问最相关的信息。如何提升检索召回的准确率?
和搜索引擎进行集成,或者使用搜索引擎的一些技术,比如为知识库创建倒排索引。
结合重排序技术。比如线性排序模型(线性回归、逻辑回归、支持向量机等等),树排序模型(决策树、随机森林、梯度提升树等等),深度学习排序模型(基于transformer的排序模型、基于文本嵌入的排序模型等等)
对查询的问题进行优化。比如查询重写、查询扩展。
2.融合的目的是便于大模型的更好地"理解"。
分隔符标记。使用特殊标记区分查询和知识库片段,帮助模型识别不同部分。比如,输入 = [查询] 查询内容 [/查询] [知识库] 知识库内容 [/知识库]
交叉注意力机制。通过计算用户输入和检索文档之间的注意力权重,模型能够更精准地选择与问题最相关的部分。
3.生成阶段交付查询的答案。如何提高回答的质量?
调节大模型回答参数。比如温度、核心采样、存在惩罚、频率惩罚等。
反馈循环。允许模型根据外部评价不断优化其生成策略,实现持续改进。
RAG的核心在于检索,自动找出用户提问最相关的知识或相关的对话历史,结合原始提问(查询),创造信息丰富的prompt,使大模型输出更精准。
四、RAG应用场景
知识库增强:RAG检索知识库中的相关内容并生成详细回答,提升知识库的交互性。
构建智能对话系统:RAG通过检索上下文信息生成自然对话,提升用户体验。
个性化推荐:RAG检索用户历史数据并生成个性化推荐,如新闻、商品等。
...