近期公司在太保学习上推出了各种架构专题的课程,由于我不知天高地厚地报了所有课程,而且需要在截止日期前全部学习完,看着每个专题恐怖的时长,以及近在咫尺的截止日期,遂突发奇想是否可以通过浏览器扩展插件实现自动学习的效果。
先尝试询问AI,看一下开发插件的难度如何

看起来并没有那么难,那么先进行需求分析:
1.在自动登录后,能够自动选择必修的、未完成的课程开始学习(视频播放)
2.可以继续之前未完成的学习然后开始梳理思路,目前能想到两种方法:一种是通过接口调用,一种就是通过脚本模拟用户点击行为。
通过浏览器抓包后,发现接口的数据都是进行加密的,并且要梳理各接口之间的调用关系,如果通过接口调用的方式实现自动化,难度太大,遂放弃第一种方案。
那么就只有第二种办法了,就是通过模拟用户的点击行为实现自动化。
梳理我在进行学习时的操作路径:
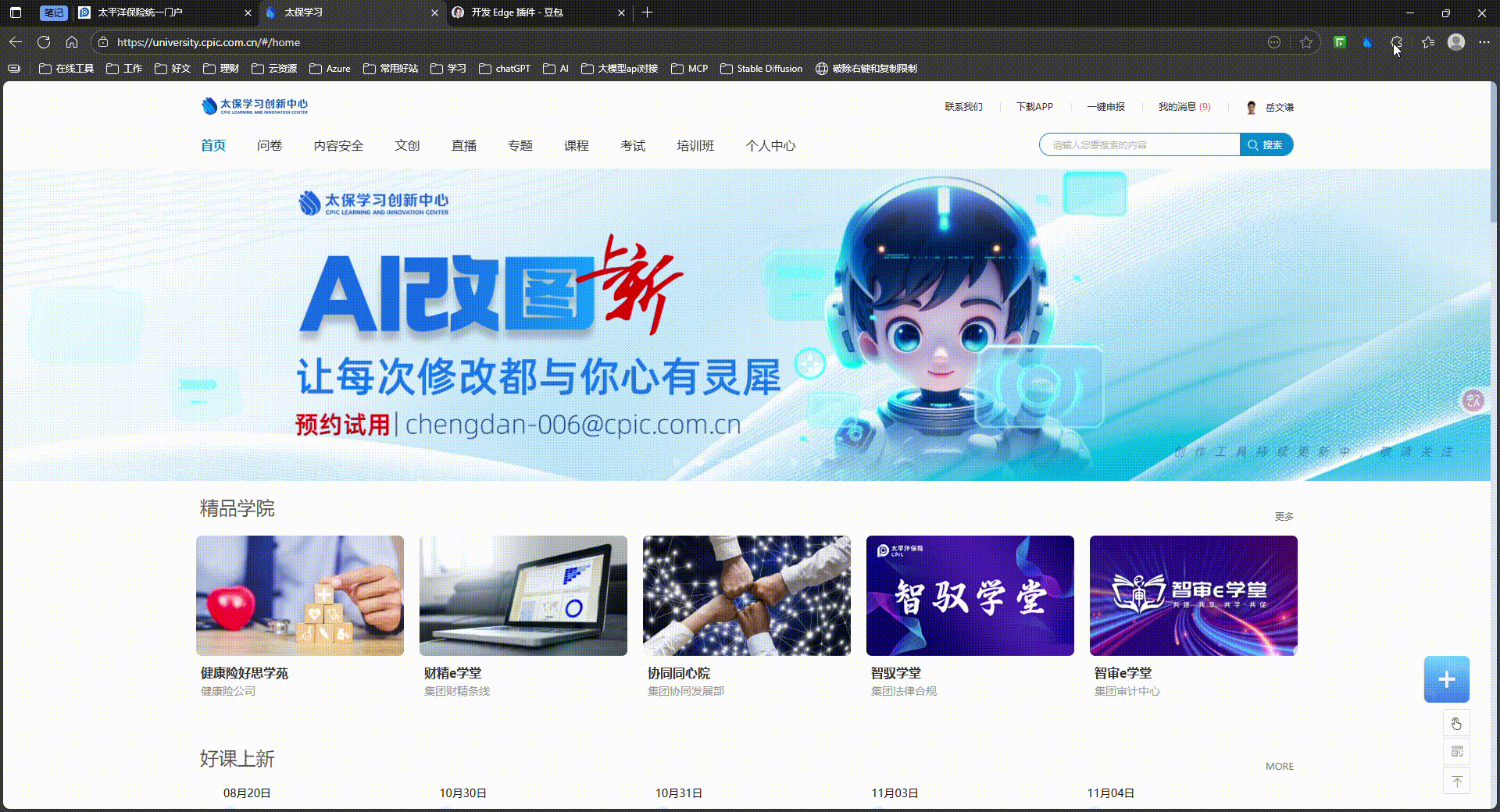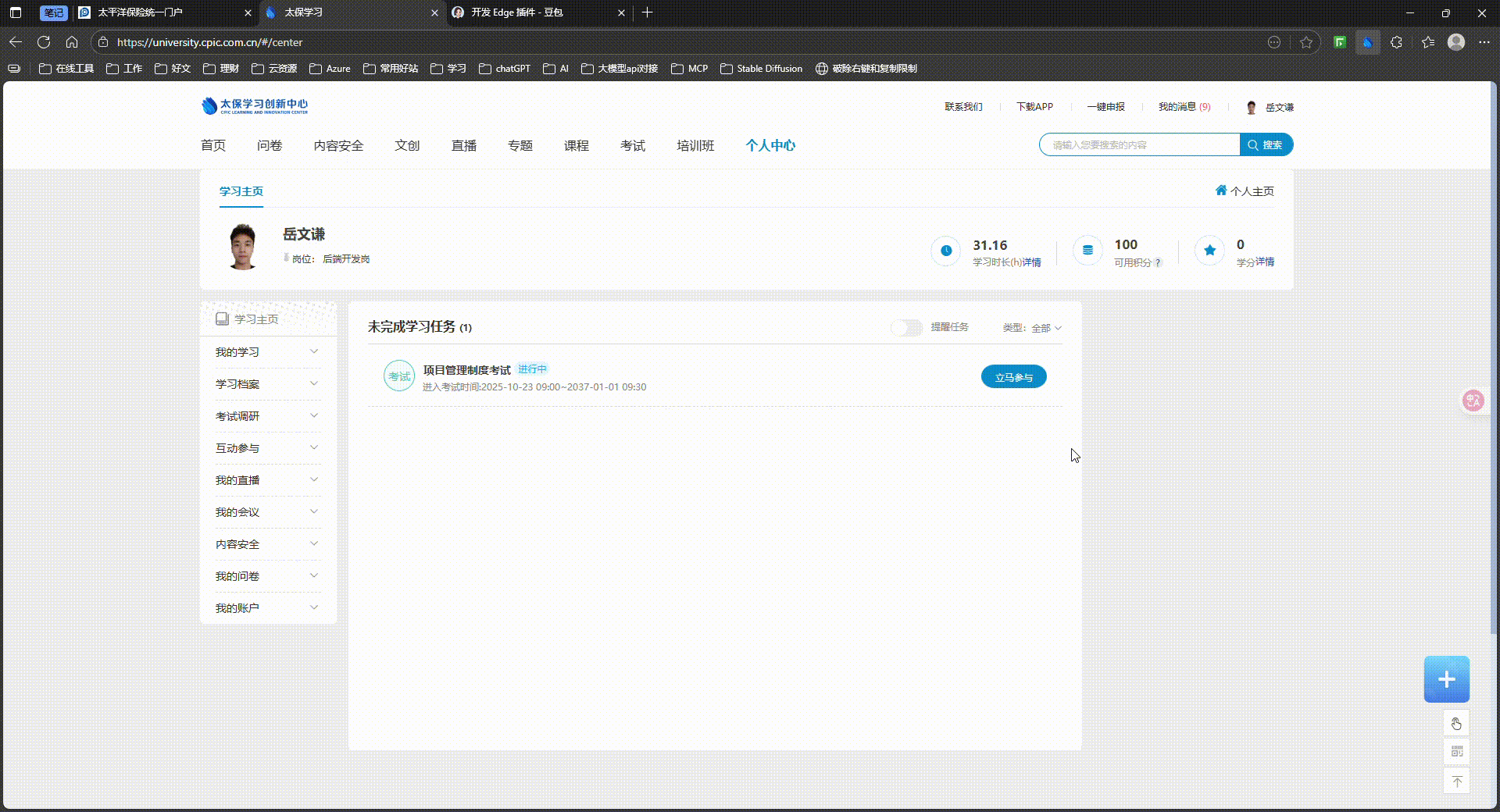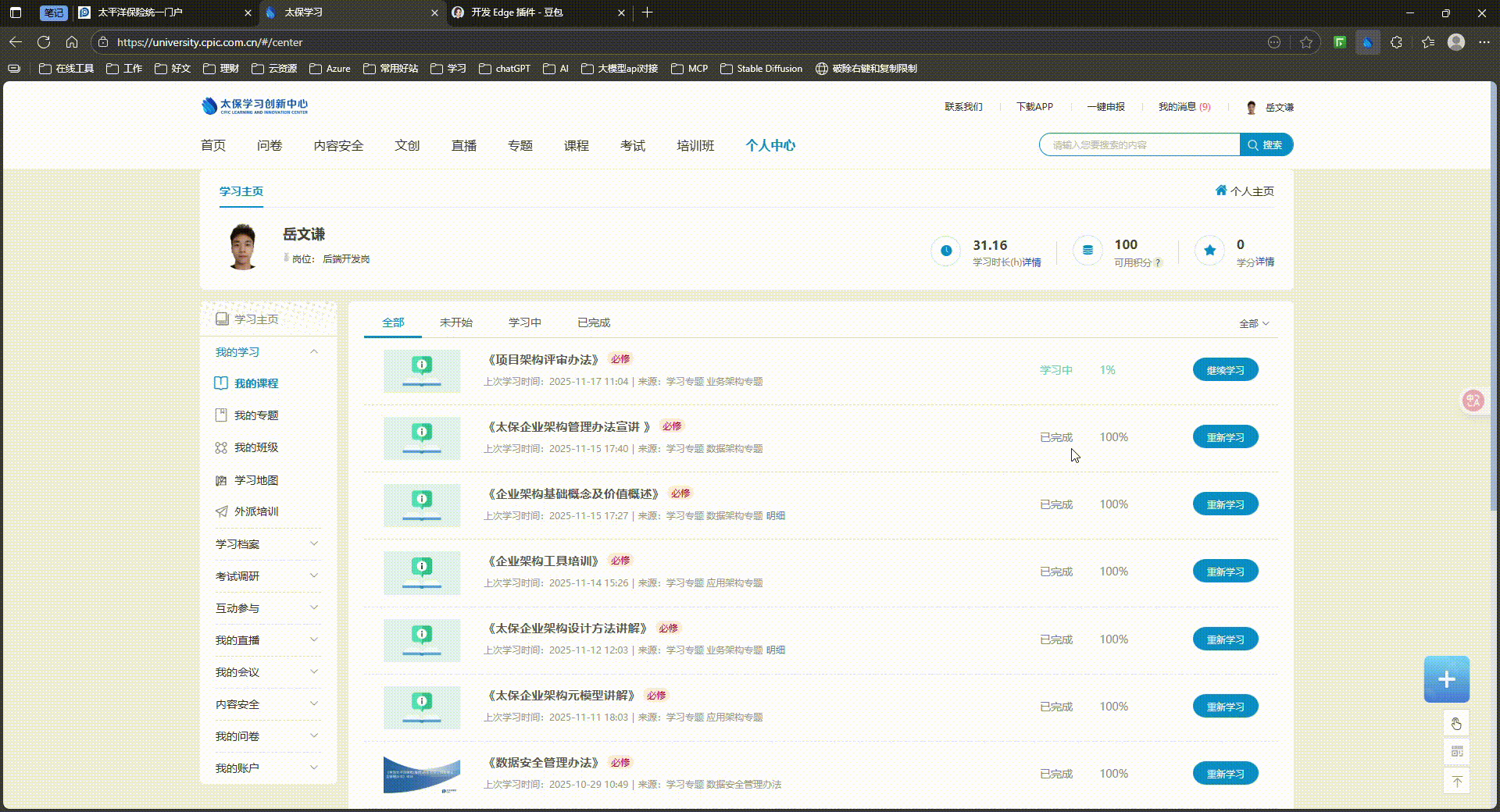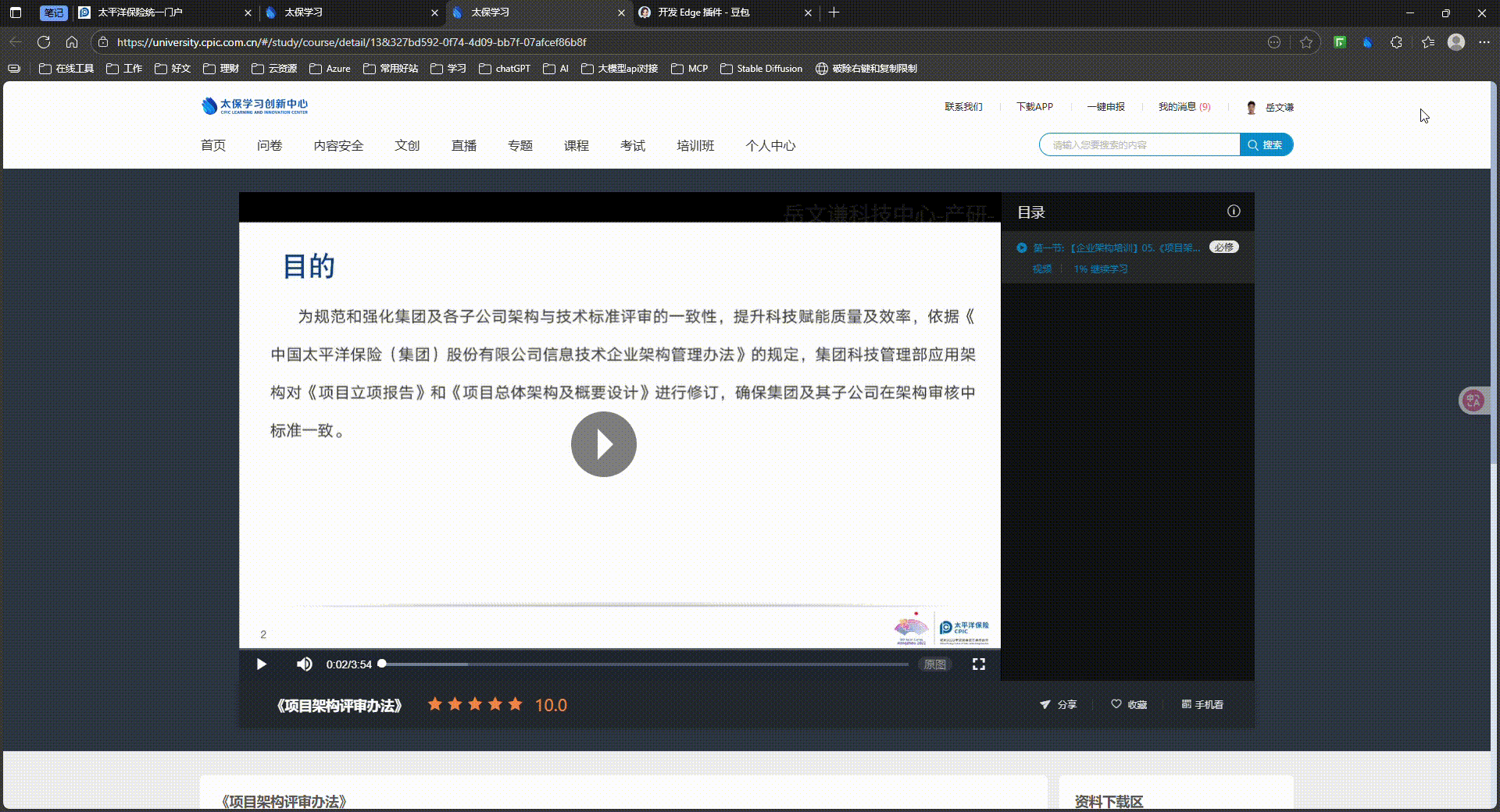
登录 → 个人中心 → 我的学习 → 我的专题
→ 选择必修的专题 → 开始学习/继续学习
→ 选择未完成的课程 → 开始学习/继续学习 → 等待视频播放完成 → 关闭课程学习页面
→ 选择未完成的课程 → 开始学习/继续学习 → 等待视频播放完成 → 关闭课程学习页面
...
→ 没有未完成的课程 → 关闭课程列表页面
→ 选择必修的专题 → 开始学习/继续学习
...
→ 没有必修的专题 → 学习完成以用户视角将操作路径梳理清楚了,现在我们需要梳理代码实现的思路,在这之前我们需要先分析页面的html结构,来确定状态判断的条件:
'个人中心'需要点击的元素:
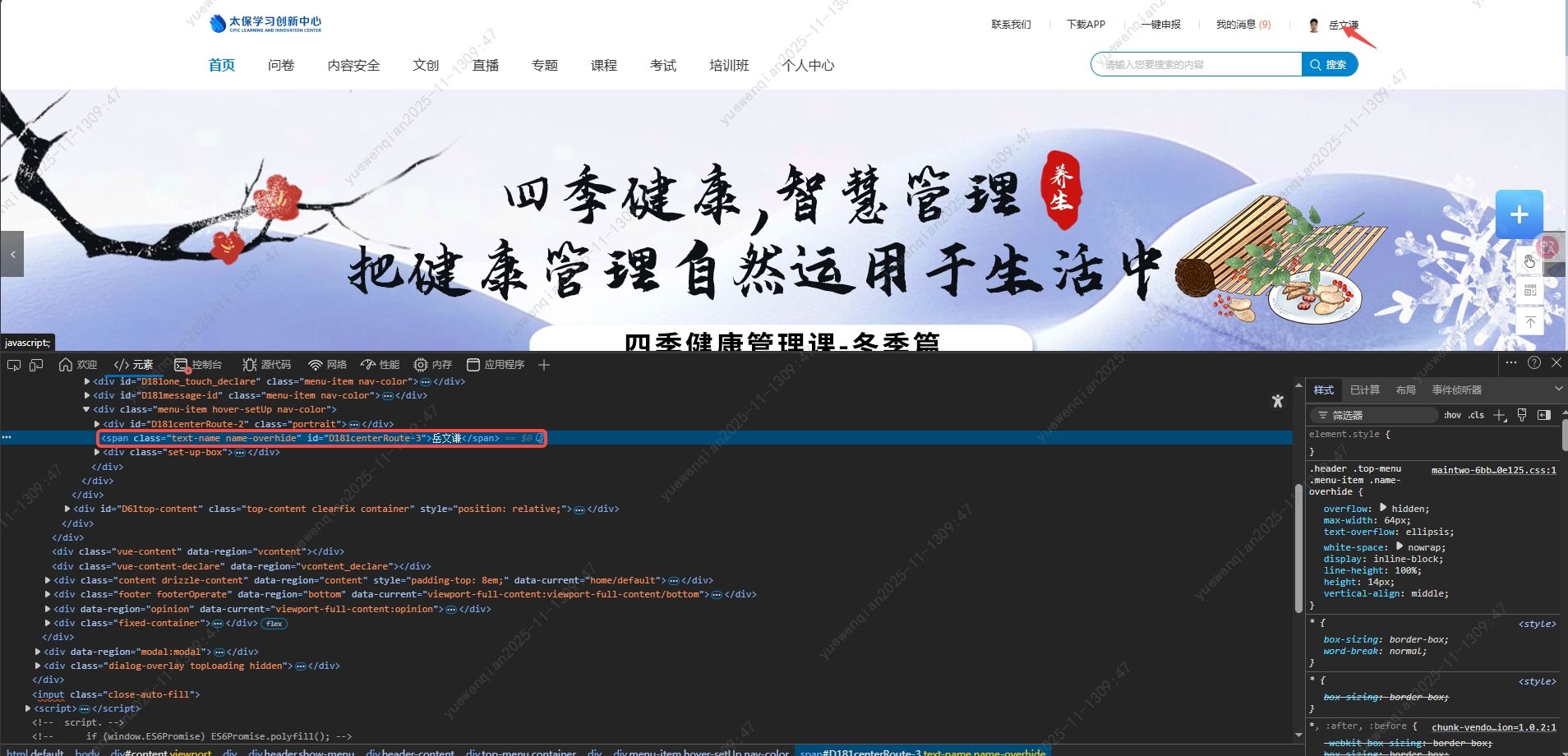
'我的学习'需要点击的元素:
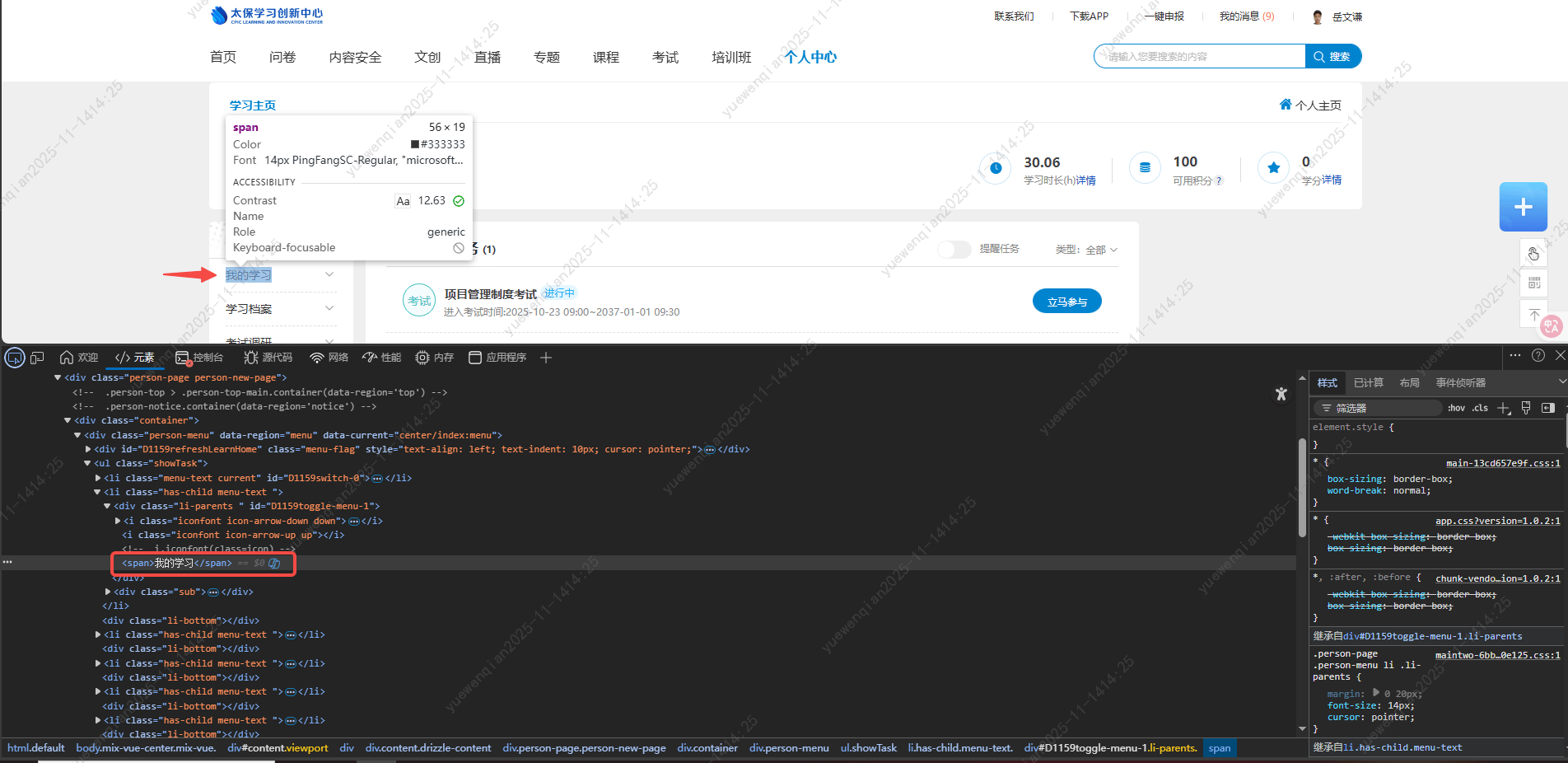
'我的专题'需要点击的元素:
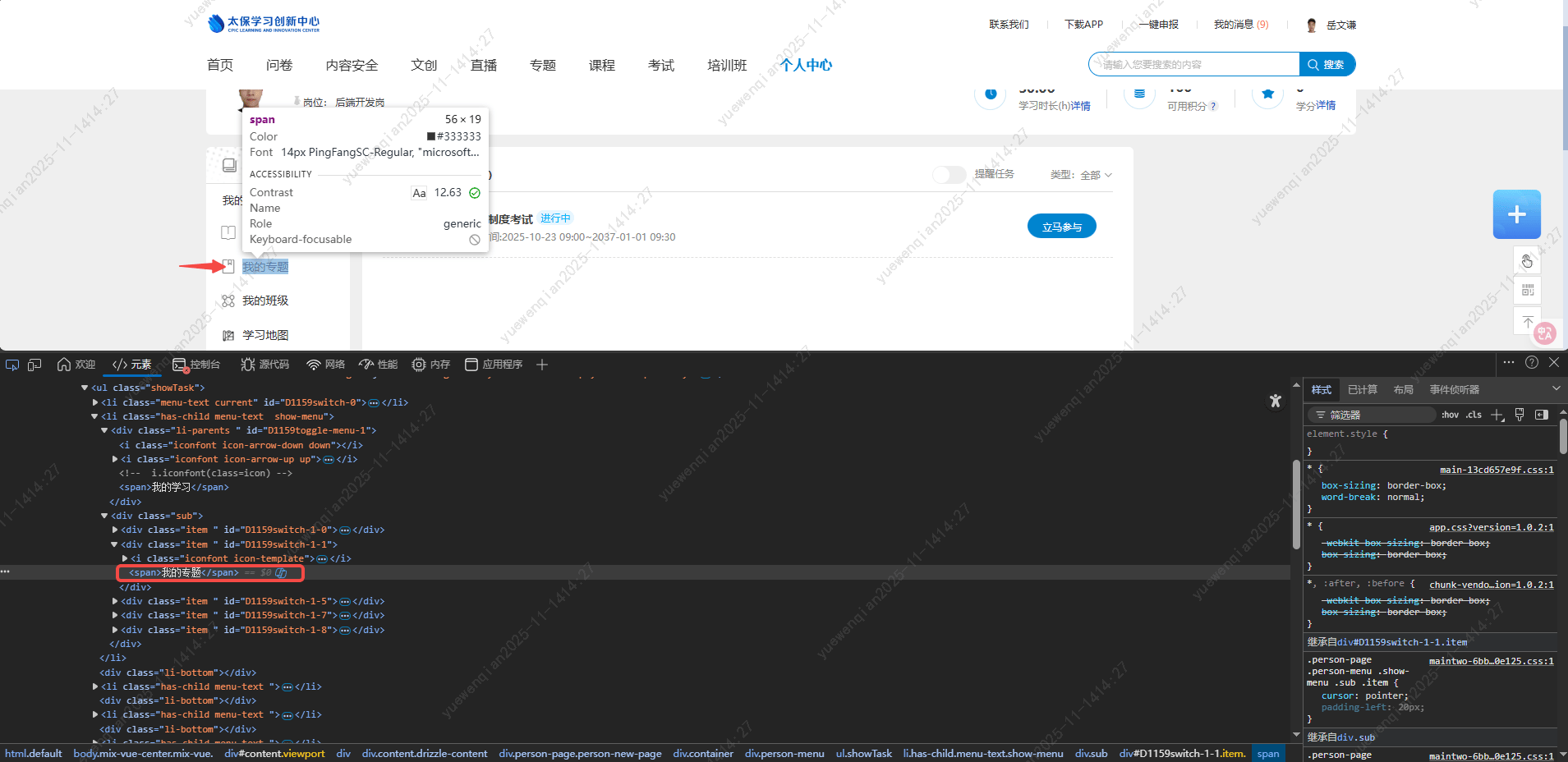
'专题列表'元素所在标签:
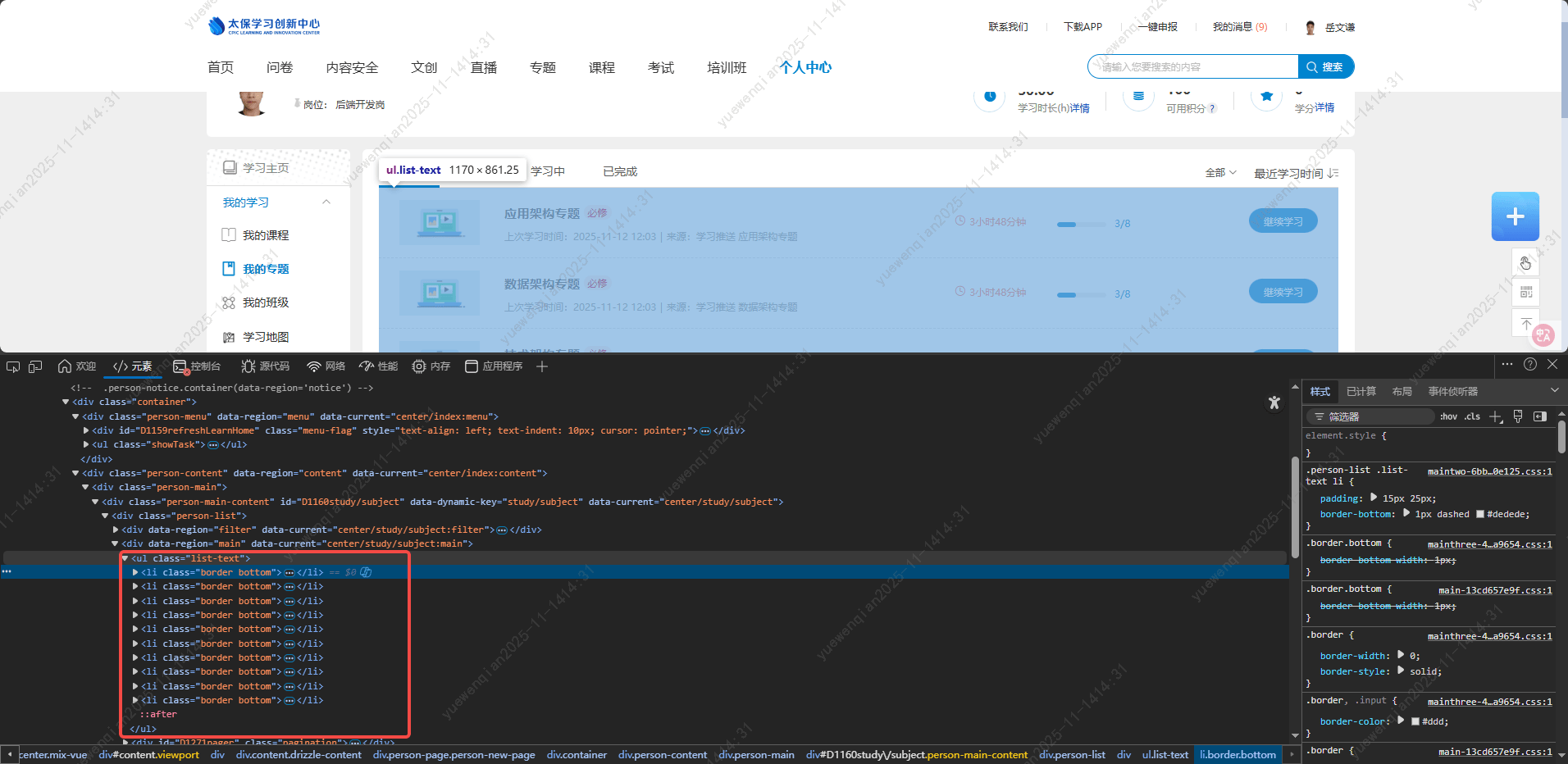
'必修标签'所在元素标签:
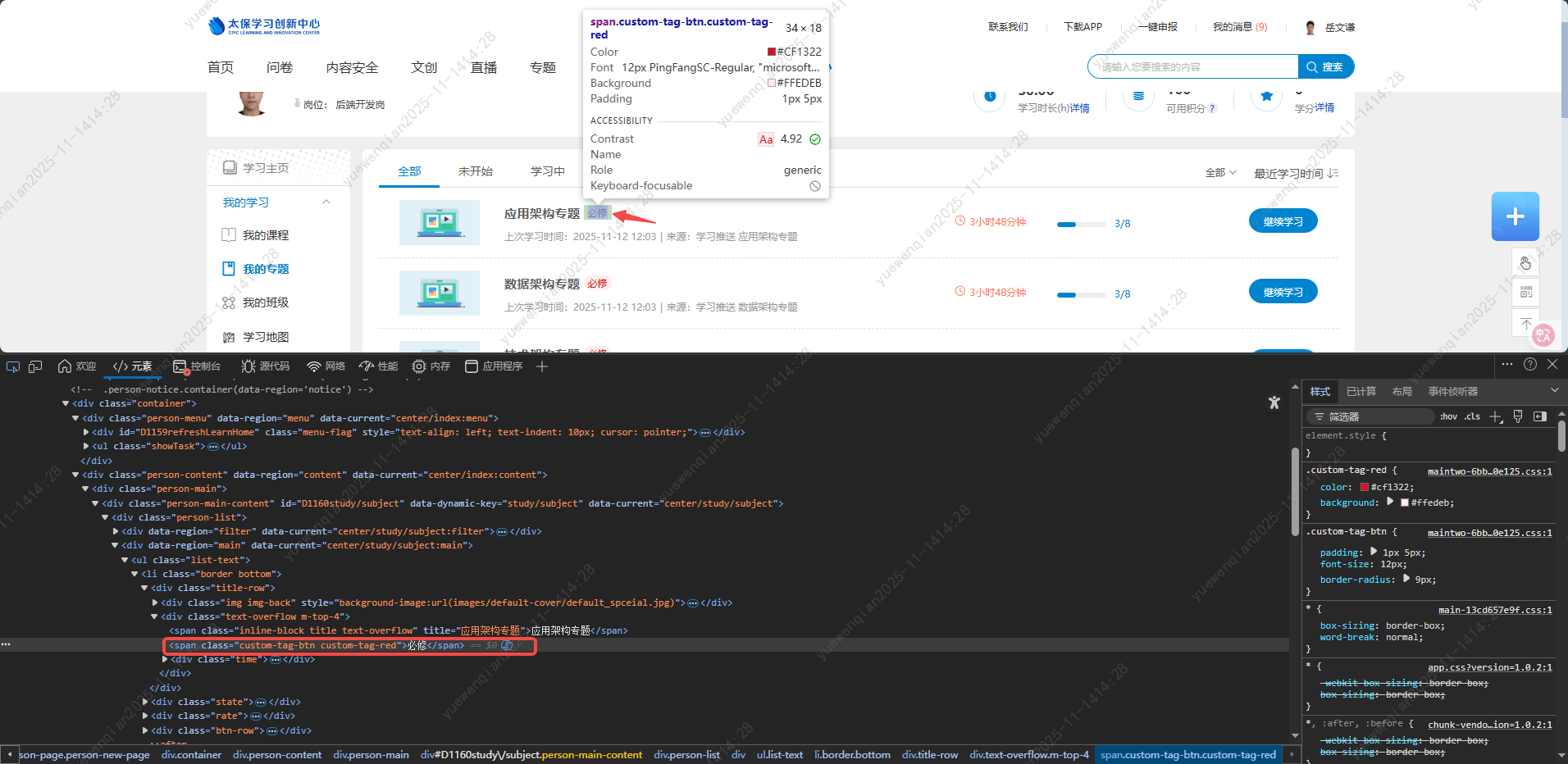
'继续学习/学习按钮'需要点击的元素标签:
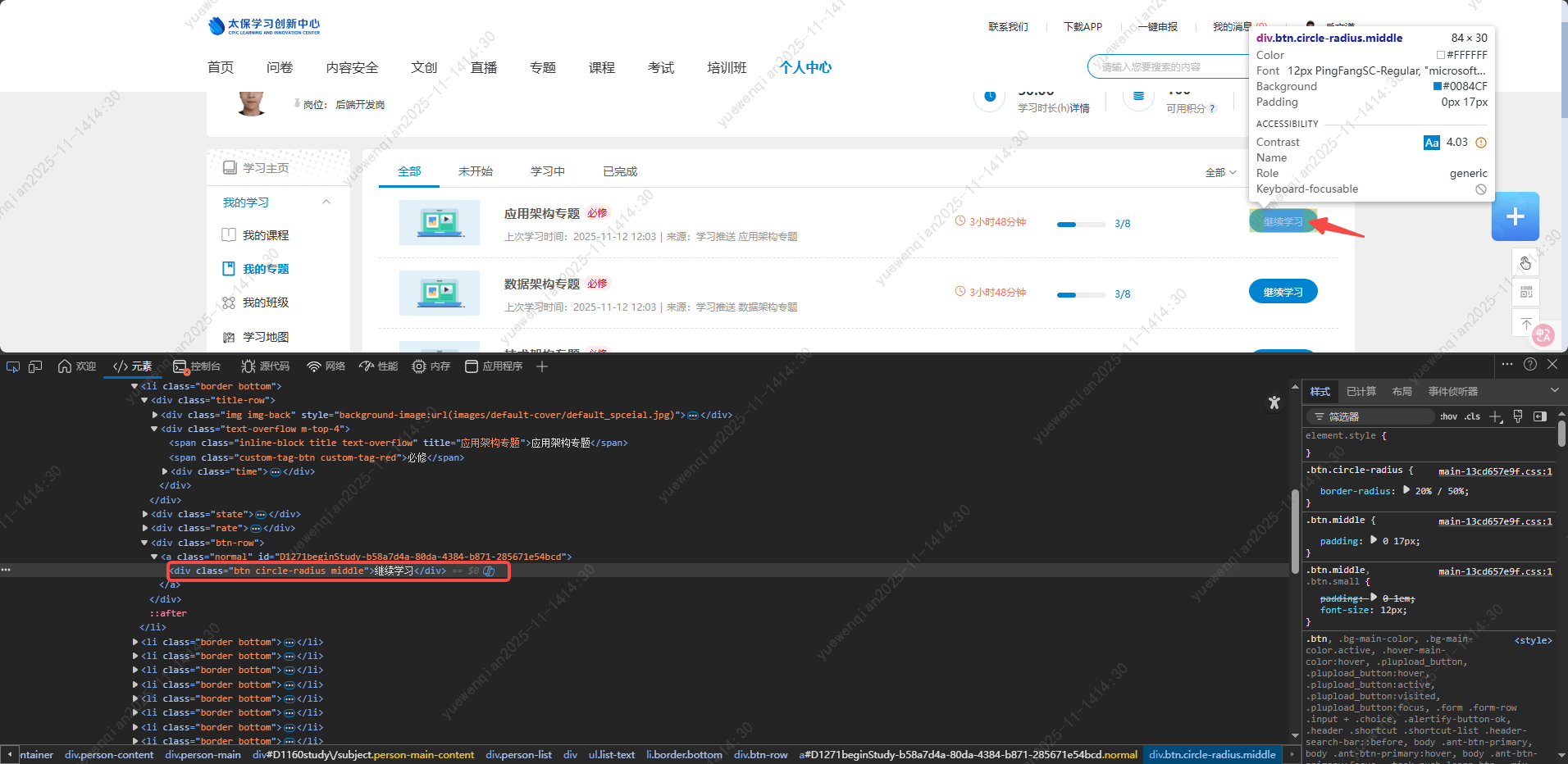
后面的元素操作,由于篇幅原因就不一一列举了。
分析完html页面元素后,接下来就是代码实现思路了:
1.点击插件图标,弹出弹窗,弹窗里有一个开关,默认是关闭的
2.当打开开关时,检错当前页面中class值为'name-overhide'的span标签并点击
3.接着等待当前页面渲染完毕,然后检索标签内容为'我的学习'的span标签并点击,然后等待2s
4.然后检索标签内容为'我的课程'的span标签并点击,等待2s
5.接着检索class名为'list-text'的ul标签
6.遍历ul标签下所有的li标签,判断当前li标签下,class名为'custom-tag-btn'的span标签的内容是否为'必修'
7.如果不是'必修',则遍历下个li标签。
8.如果是'必修',则判断当前li标签下,class名为'circle-radius'的div标签的内容是否为'开始学习'或'继续学习'。如果没有命中,则遍历下个li标签;如果命中,则点击该div,等待2s。如果循环结束都没有命中,则在插件弹窗上增加'学习已全部完成'字样。
9.点击div跳转到新页面后,遍历在class名为'catalog-state-info'的div标签下,所有的名为'item'的div标签,判断该div下是否存在内容为'已完成'的span标签。如果不存在,则点击该div下class为'inline-block'的div,等待2s; 如果存在,则遍历下个div标签
10.在打开的课程视频播放界面,每隔60s判断class名为'progress'的span标签的内容是否等于'100%',直到命中条件退出循环。
11.退出循环后,回到专题列表页,继续步骤6。
思路有了,接下来就是代码实现了,尝试使用AI替我们实现,这里采用渐进式代码生成,先实现一部分功能:

按照AI给出的步骤,创建项目文件,粘贴代码,并在浏览器中加载执行,发现存在两个问题:
第一个问题就是存在中文乱码问题;第二个问题点了开关,看起来没有反应

针对这两个问题,尝试让AI给出修复后的代码:

可以看到改动后的代码添加了字符<meta charset="UTF-8"> ,以及添加了tabs权限,并且在关键步骤加了一些日志打印。修改代码后,再次尝试执行。
乱码问题得到了修复:
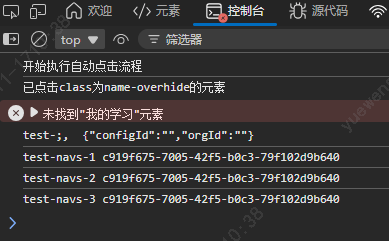
没有反应的问题,根据日志可以分析出原因:由于个人中心页的加载时间超过了2s,所以未能正确检索我的学习 元素
尝试优化思路,并让AI进行实现:

执行优化后的代码,整个过程很丝滑,看起来没有什么问题了,那么继续实现后面的功能:

检查了一下生成的代码,直接复制粘贴和执行,可以看到完美执行了我的思路:
由于我对前端知识的不足,执行到这里我突然想到了新的问题:
1.在当前页面开启组件后,是仅在当前页面执行,还是打开的所有标签页都会执行
2.当在课程列表页点击学习按钮,跳转到课程学习页面时,插件还会在课程学习页面继续执行吗?以及课程学习页面执行完毕后,该如何回到课程列表页面并继续执行插件?
先来看看AI怎么说:
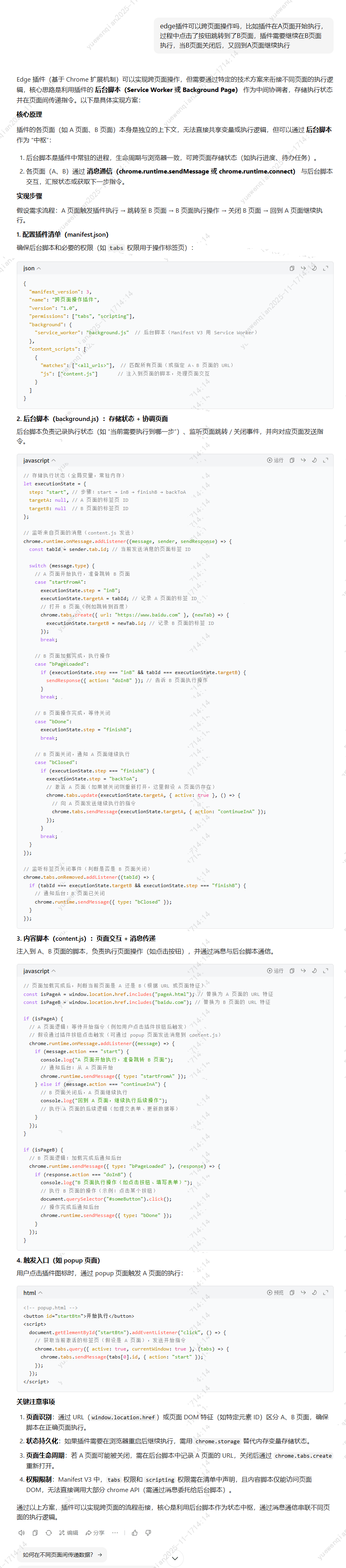
也就是说需要一个后台脚本来协同操作,并且还需要记录跳转页面的tabId。看AI给出的例子,可以在指定跳转页面url的同时,获取到这个tabId,但是通过分析页面元素,没办法简单的获取跳转页面的url:
新页面的url并没有直接暴露在a标签中,难道新页面的url可以通过指定前缀拼接这个id获取?

显然和上面a标签中的id不是一个值,说明这个跳转链接应该在js中动态拼接的,那么就需要转换思路了。后台脚本如果需要跨页面操作,tabId是必不可少的,既然不能简单的从页面元素中获取tabId,那么是否可以在点击继续学习 按钮的同时获取tabId呢?

根据AI给出的回答,是的可以的,但是细看AI给出例子,直接通过目标元素中的href获取跳转链接,这个地方可能是有问题的,因为a标签中的href并没有值,它也说明了可能是JS 动态跳转(如按钮点击后 window.location.href 赋值),所以展开追问
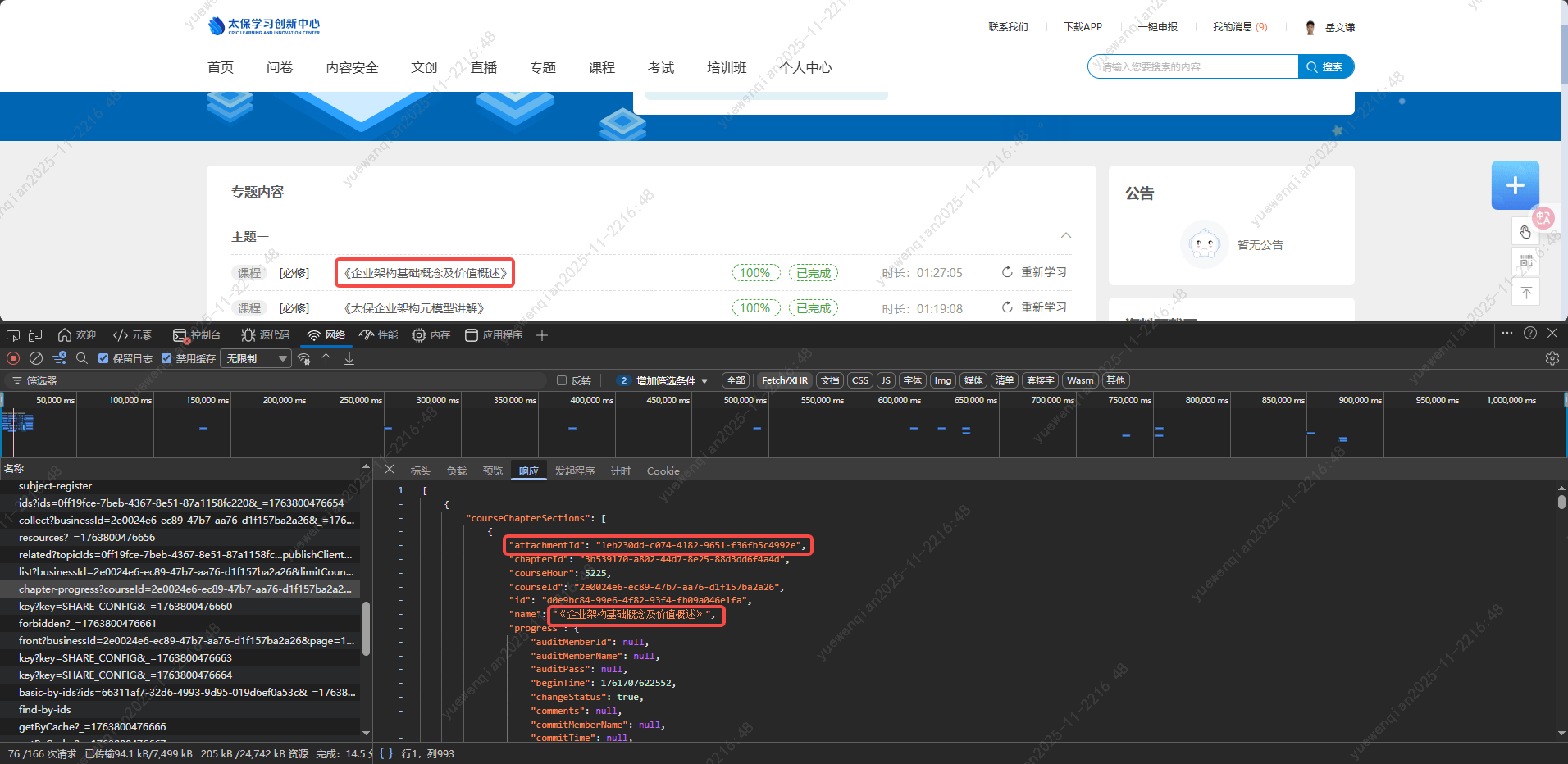
AI给出了拦截与模拟的实现思路,我不禁开始思考,为了获取tabId加了一大堆的代码,或许有更简单的实现方式。既然是通过JS动态生成的url,那么一定有接口响应了这部分信息。于是开始抓包进行分析,当点我的专题 时,请求了三个接口:

分别查看三个接口的响应,通过比对响应信息和跳转链接,终于定位到了具体字段,跳转链接拼接的路径对应/personCourse-list 中的versionId 字段:

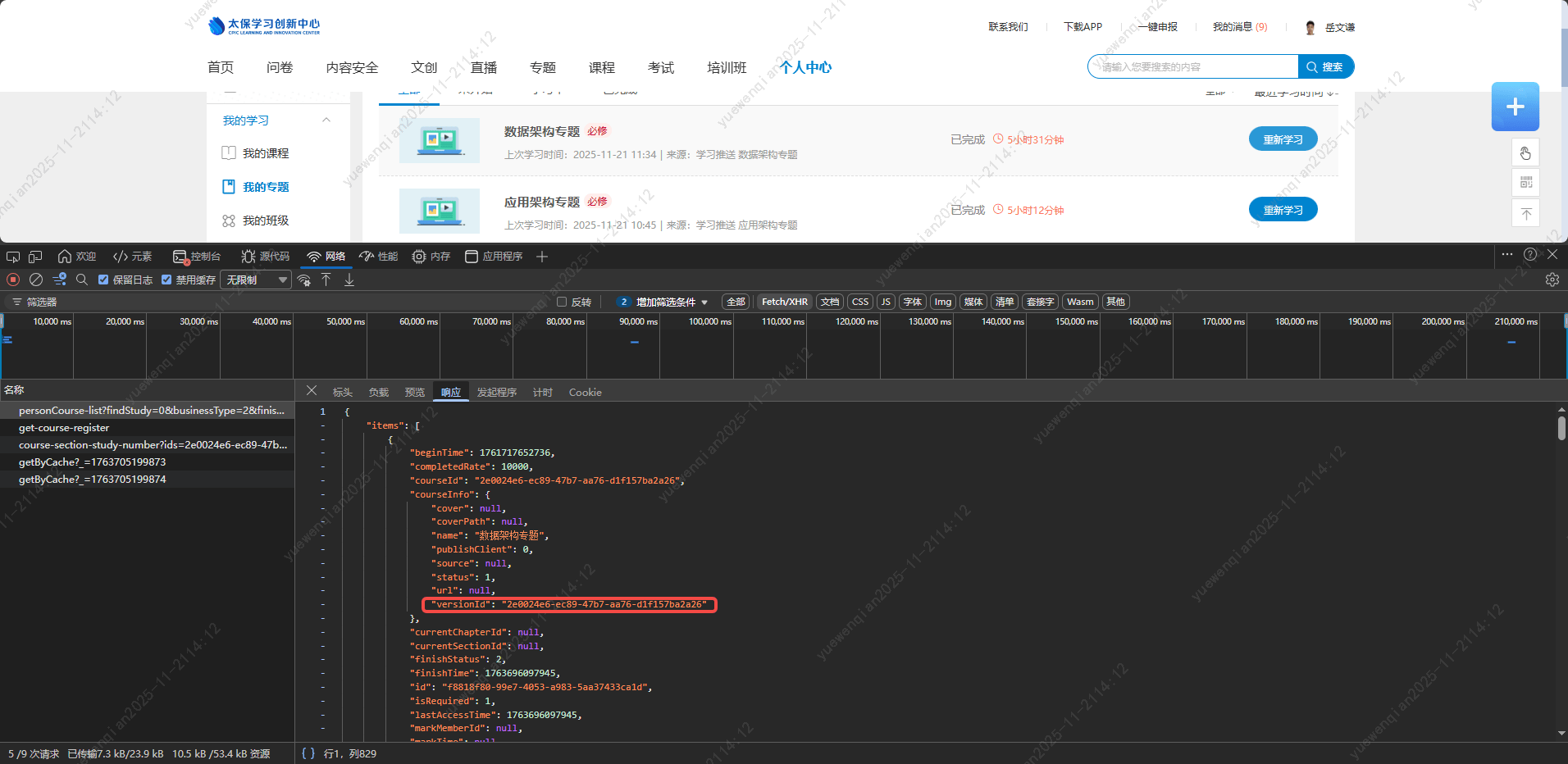
而a标签中的id则是通过前缀拼接/personCourse-list 中id 字段组成的:

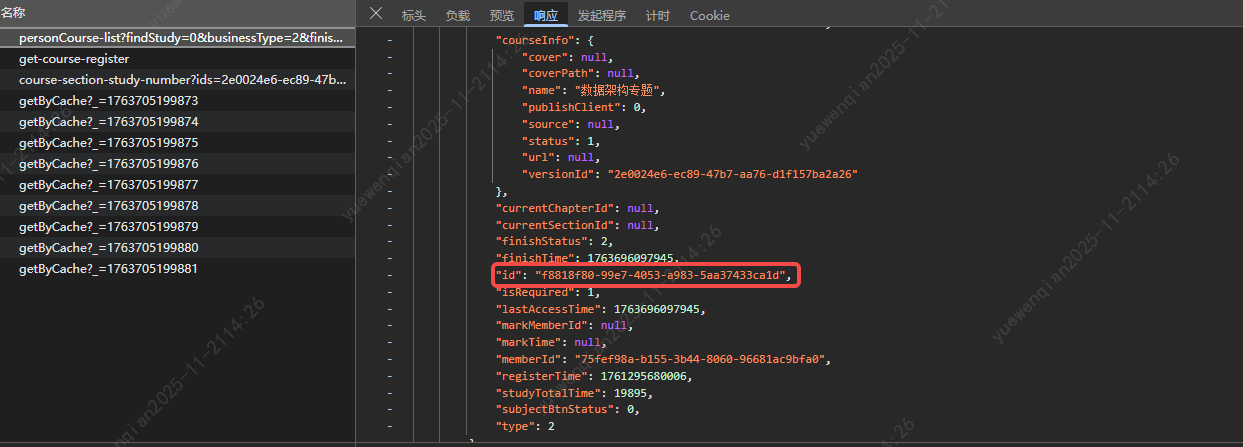
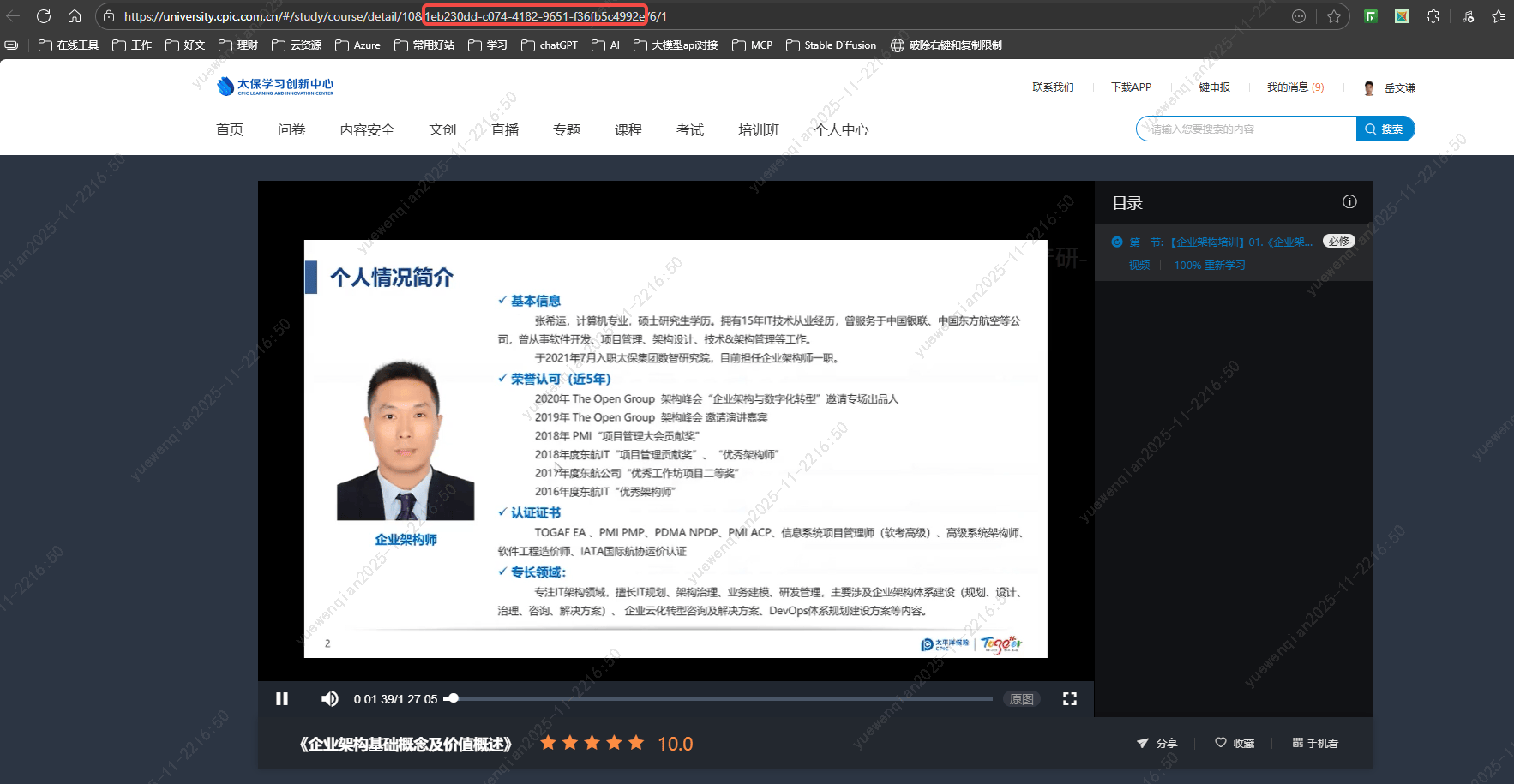
所以我们可以直接监听/personCourse-list 接口,通过a标签的id匹配响应列表,获取versionId 字段的值,然后在拼接固定的路https://university.cpic.com.cn/#/study/subject/detail/ ,最终就可以获取到这个按钮的跳转url,从而可以通过url创建标签页,直接获取到tabId。
同理,也可以分析出专题课程列表页面的跳转url拼参逻辑:
确认技术实现细节后,重新整理思路,加入页面通讯逻辑,得到了新的流程图:
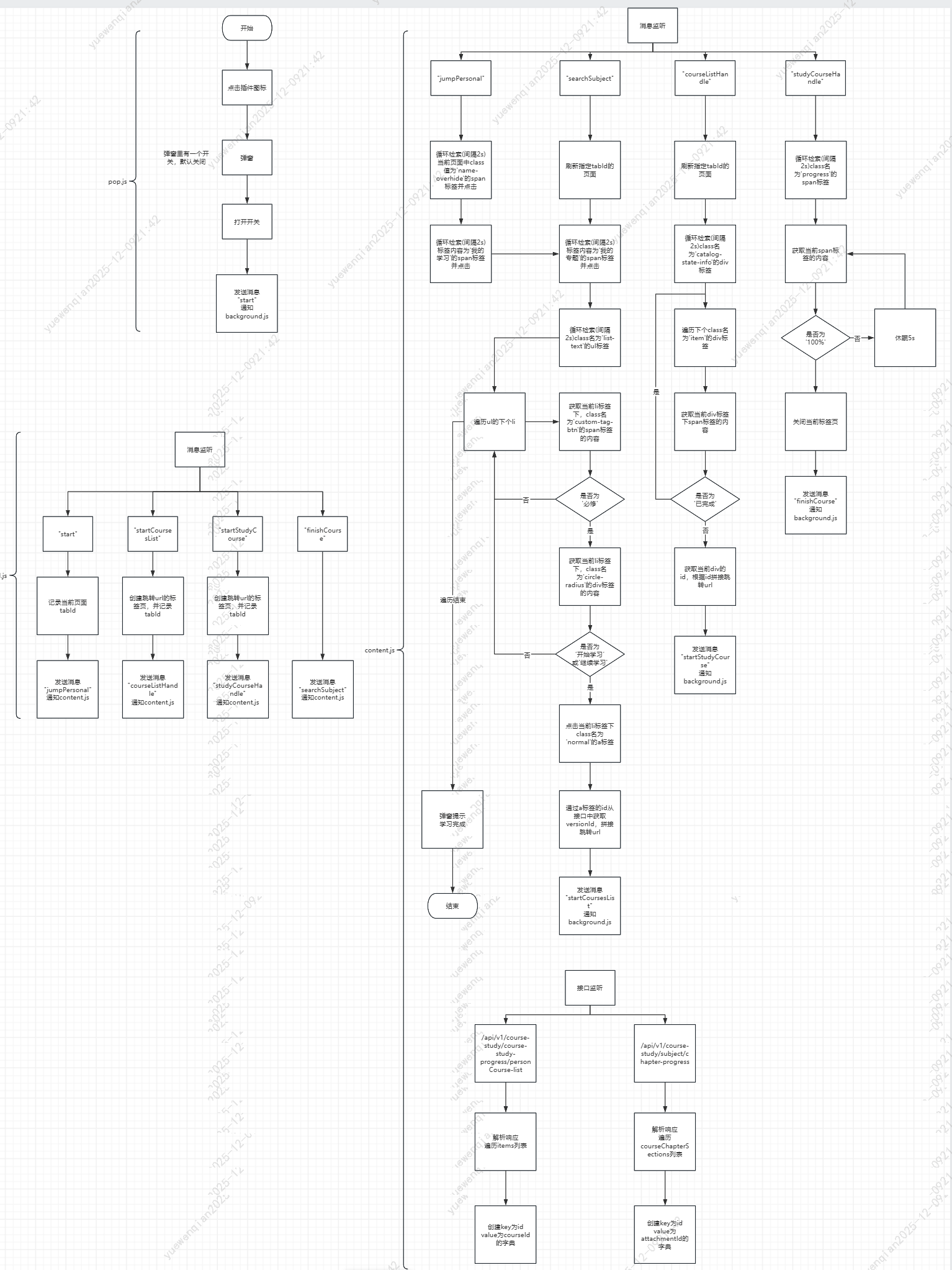
流程图已经画好了,下面就可以根据流程图来实现功能了。
对于复杂需求的代码生成,有两个关键点:一个是我们对于AI理解到的内容没有把握;另外一个就是生成的代码量较大,导致调试难度大。针对这两个点,我们在编写prompt时,可以对功能进行拆分并采用渐进式的代码生成策略,同时允许AI提出疑问,并且需要复述理解到的功能细节,确保需求是对齐的。

可以看到,遵循这个流程,不光可以确保对齐理解,甚至可以让AI主动考虑到我们忽略掉的细节。
运行给出的代码,观察控制台日志,验证当前单元的功能。
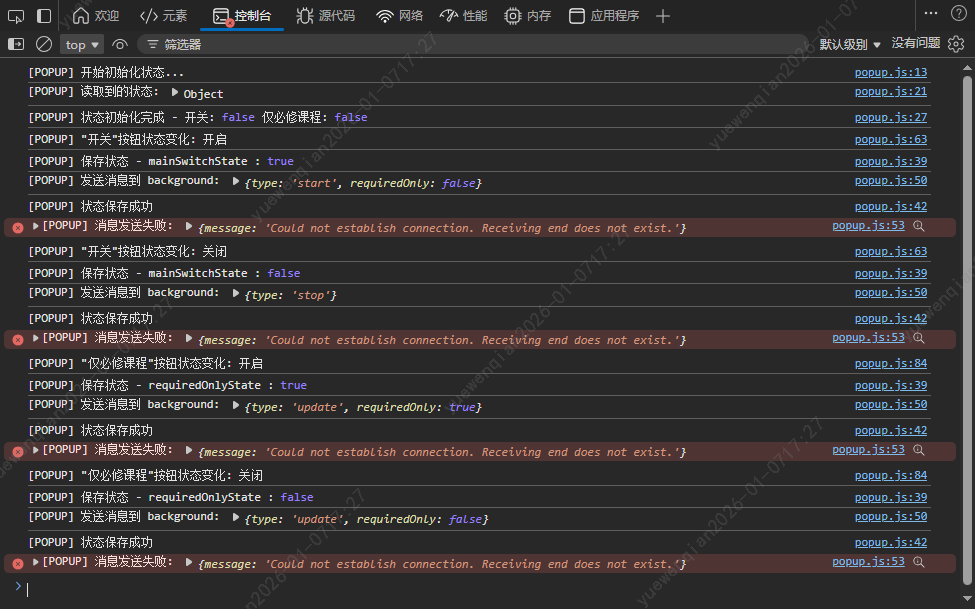
功能没什么问题,并且重新打开插件能够记住插件按钮状态,只不过发送消息给backgroud.js时会报错,因为background.js还没实现该功能,下面开始让AI去生成background.js的代码。
这里有一个细节,我在提问时又重新复述了一遍开头的我们定下的规则,这是因为在进行一段功能的代码生成后,由于上下文的限制,大模型可能遗忘了规则,所以保险起见,我们需要重申规则。

运行给出的代码,根据场景进行测试,观察日志输出,发现有一个问题,在popup.js发送'update'和'stop'消息给background.js时,background.js并没有转发消息给content.js。

为了解决上面的问题,要求AI对现有代码做出修改。
要求AI修改代码时,最好将代码现状复制到prompt中,哪怕现在的代码是在同一个会话窗口生成的,不然可能会出现AI将之前有问题或者废弃的代码作为现状进行代码生成的现象,这可能会导致生成的代码问题越改越多。
重新进行验证
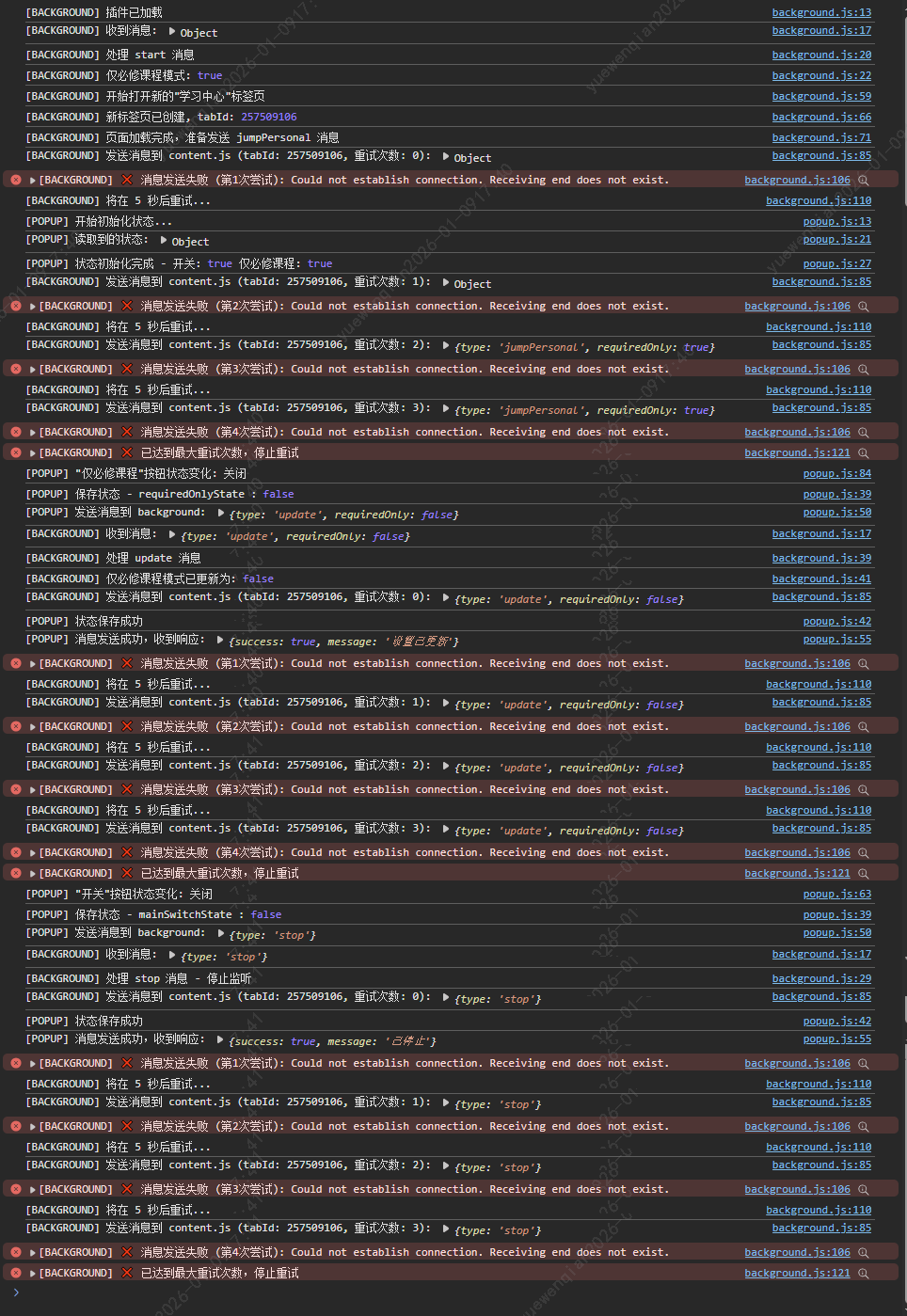
可以看到'start'、'update'、'stop'都转发了消息,不过由于content.js的代码还未开发,所以发送失败了,接下来开始实现content.js的功能。
由于content.js的功能包括分支结构,在进行功能描述需要采用结构化的语言,清晰地描述分支流程。这里没有特别要求,可以采用序号的方式,也可以采用更为专业的mermaid语法,只要能够描述清楚即可。
仔细看了下生成的代码,发现有一段功能理解有偏差
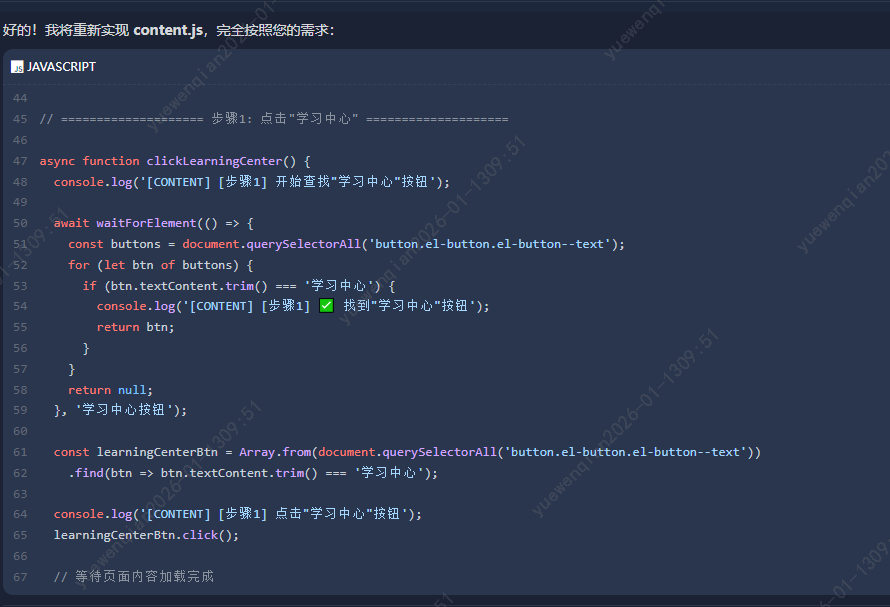
这段功能要求实现的是检索标签内容为'我的学习'的span标签并点击 ,却被理解成学习中心 ,可能受到之前上下文中backgroud.js中的内容影响。由于目前上下文的长度肯定超过了模型限制,并且上下文中还存在大量的无用代码(修改前)代码,白白浪费token,索性重开一个会话窗口继续代码生成。
由于我使用的是套壳网站(api的调用方式),该网站超出token上限后会截断回复,所以接下来用回了claude官网的网页版对话。
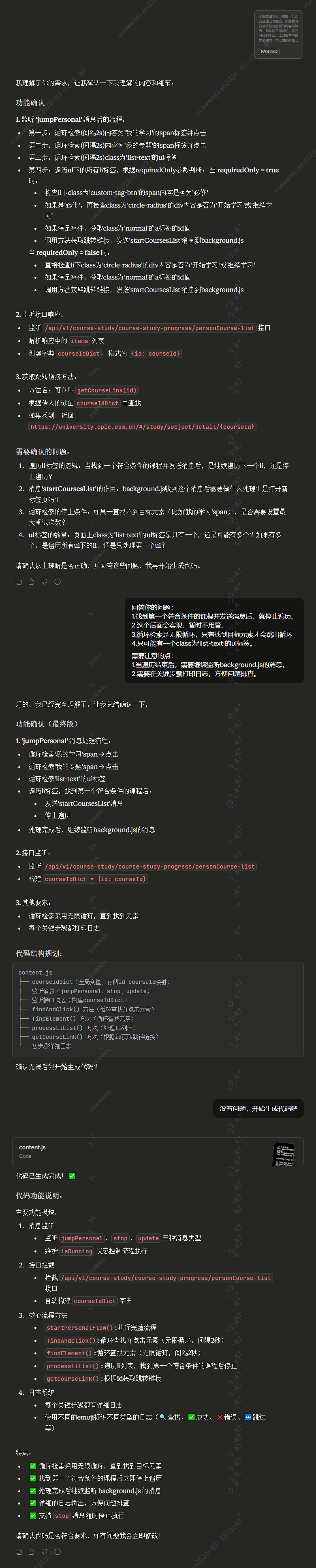
该提问的prompt:
生成的content.js内容:

验证代码,观察页面跳转和控制台打印。
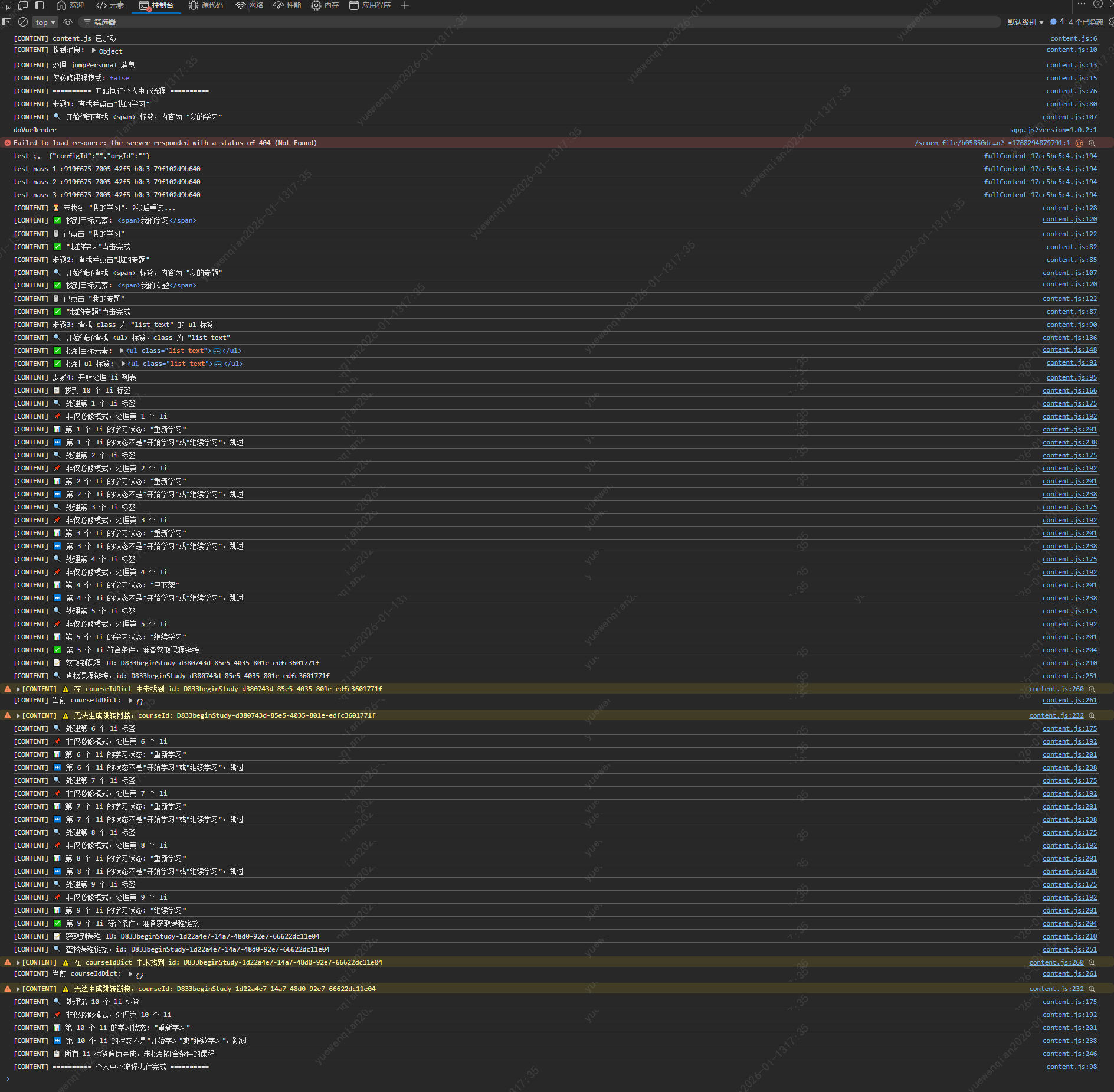
出现了在 courseIdDict 中未找到 id 的日志,查看courseIdDict的值,发现是空的,说明在courseIdDict未构建完成时,就已经找到了符合条件的id,尝试让AI修复这个问题。


重新验证发现还是有问题,一直在等待courseIdDict构建。
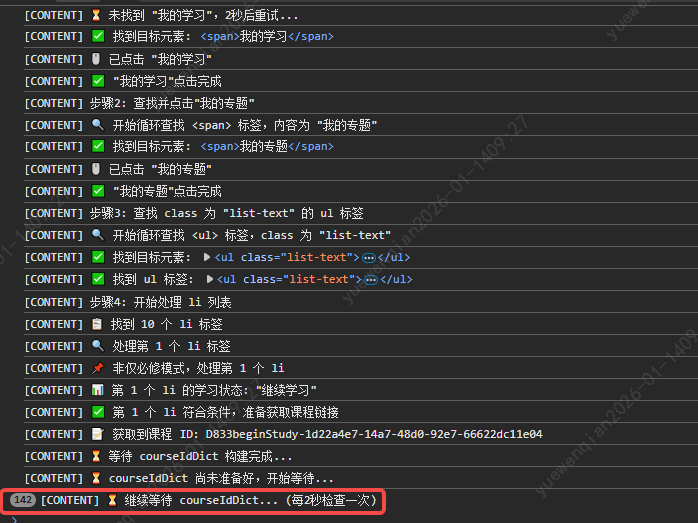
后面尝试让AI分析原因,并给出解决办法。经过各种调试,发现还是不行,由于快触发claude官网的限额了,所以只能暂时放弃了。
后续完整对话见浏览器扩展功能流程确认 | Claude,可以看到完整的调试内容。